
dbt: Was das Data Build Tool auszeichnet – und was es nicht ist

dbt (Data Build Tool) ist ein Open-Source-Tool, das Unternehmen dabei unterstützt, Rohdaten effizient und strukturiert in hochwertige Datenprodukte zu transformieren. Dabei setzt dbt auf Daten, die sich bereits im Data Warehouse befinden. Somit ist dbt klar auf den Transformationsteil (T) im ETL/ELT-Prozess spezialisiert.
In dbt werden sogenannte Models als SQL-Dateien entwickelt, die jeweils eine klar beschriebene Transformation enthalten. Diese SQL-Transformationen werden von dbt orchestriert und per Push-Down-Logik direkt im Data Warehouse ausgeführt, wodurch dessen Rechenleistung optimal genutzt wird.
dbt ist bewusst fokussiert – und das ist eine Stärke:
Was dbt kann:
- Transformationen im Data Warehouse strukturieren und versionieren
- Abhängigkeiten (Lineage) automatisch ableiten
- Dokumentation und Metadaten (Artifacts) erzeugen
- Integriert Best Practices aus Software-Engineering in die Entwicklung von Datenmodellen z. B. Git, CI/CD, Modularisierung oder Tests
Was dbt kann nicht (bzw. nicht als Kernfunktion):
- Ingestion/Datenanbindung (APIs, Files, Streaming) in das Warehouse übernehmen
- als Universal-Orchestrator für beliebige technische Tasks dienen (dafür nutzt man meist Airflow, Dagster etc.)
Stattdessen liefert dbt ein stabiles Engineering- und Metadaten-Fundament für Transformationen und analytische Datenprodukte. Die Entwicklung mit dbt kann auf unterschiedliche Weise erfolgen, wobei zwischen Engine und Plattform zu unterscheiden ist. Es gibt dbt Core (das Open-Source-Framework) und dbt Cloud (die Managed Plattform). dbt Cloud nutzt intern zunehmend die neue, in Rust geschriebene Fusion Engine für deutlich schnellere Kompilierungszeiten.
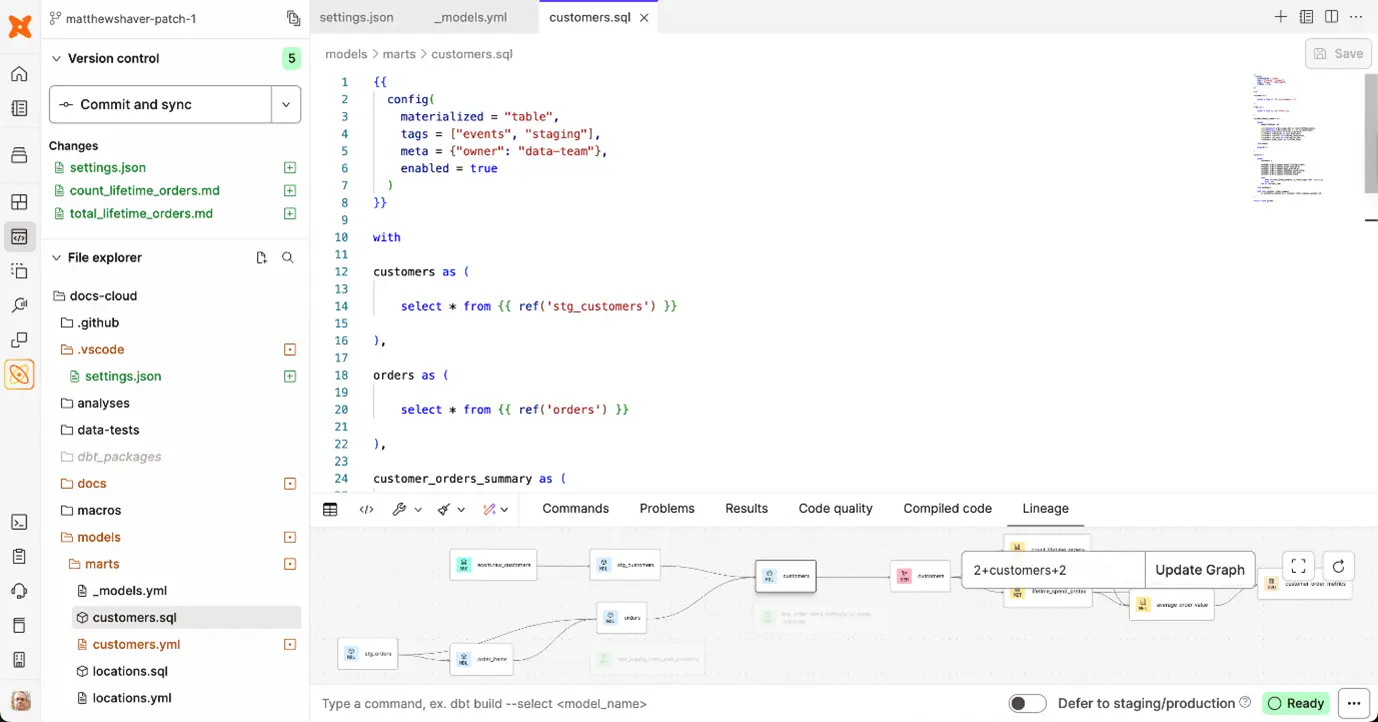
Ein Screenshot der Cloud-UI (Abbildung 1). Auf der linken Seite werden die vorgenommenen Änderungen angezeigt, darunter befindet sich der Datei-Explorer. Rechts davon sind der Datei-Editor sowie die Lineage-Ansicht angeordnet. Am unteren Rand der Oberfläche ist die Kommandozeile zu sehen.
SQL-first: Transformation dort, wo die Daten liegen
dbt setzt auf einen SQL-first-Ansatz, bei dem Transformationen direkt im Data Warehouse in sauberem SQL umgesetzt werden. Durch die Kombination mit Makros können Models modular aufgebaut, wiederverwendbar und gut strukturiert gestaltet werden. dbt sorgt dafür, dass die Models in der richtigen Abhängigkeitsreihenfolge ausgeführt werden, und bietet mit Makros, automatisierten Tests und Dokumentation eine hohe Wartbarkeit.
Gleichzeitig lässt sich der Code über Git verwalten, inklusive Branches, Pull Requests und Reviews, sodass nachvollziehbar in größeren Projekten und Teams gearbeitet werden kann. Mithilfe des dbt-build-Befehls können Models zusammen mit allen Upstream- oder Downstream-Abhängigkeiten ausgeführt werden. Dadurch wird der Entwicklungsprozess, das Deployment und die Abhängigkeiten klar geregelt.
Jinja und Makros in dbt
dbt kombiniert SQL mit Jinja-Templating und macht ein Datenprojekt damit zu einer Art Programmierumgebung für SQL. Mit Variablen, Bedingungen, Schleifen und wiederverwendbaren Makros lassen sich wiederkehrende Aufgaben lösen, ohne dass die fachliche Logik in unleserliche Konstrukte abdriftet.
Beispiel: Dynamische Aggregation (SQL + Jinja)
Das Beispiel (Abbildung 2) zeigt, wie mithilfe der Jinja-Template-Engine ein statisches SQL flexibel gemacht wird. Zunächst wird eine Variable als Liste von Ländercodes erstellt, gefolgt von einem Select-Statement, das ein Model mit dem Namen „fct_sales“ mittels ref()-Makro referenziert. Die darauffolgende Schleife iteriert über jedes Element in der Variable „countries“ und setzt nach jedem Element ein Komma, außer nach dem letzten.
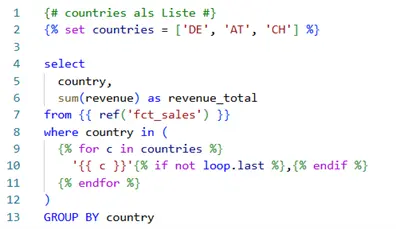
Damit können Entwicklerteams konsistente Strukturen aufbauen, Standardlogik zentral pflegen und repetitive Arbeit reduzieren. Gleichzeitig bleibt der Kern weiterhin SQL – transparent und gut reviewbar.
Für Debugging ist wichtig: Jinja wird zur Kompilierzeit-Zeit ausgeführt, bevor das SQL an das Warehouse weitergegeben wird. Dadurch kann man das kompilierte SQL einsehen und analysieren – gerade bei komplexer Logik sehr hilfreich.
Makros bergen auch das Risiko von Überabstraktion. Eine gute Faustregel ist: Makros dort einsetzen, wo sie Wiederverwendbarkeit und Klarheit erhöhen – nicht, um einfache Logik „zu verstecken“.
Kernkonzepte und Features von dbt
dbt ermöglicht es, Datenpipelines klar, nachvollziehbar und automatisiert zu gestalten. Mit Models, Referenzen, Materializations, Tests und Snapshots lassen sich Abhängigkeiten, Datenqualität und Historie direkt abbilden – ideal für transparente und effiziente Projekte.
Models, ref()und DAG (Lineage)
In dbt wird mit Models gearbeitet, die als SQL-Dateien definiert sind. Über {{ ref(‚…‘) }} referenziert man andere Models. Daraus erstellt dbt automatisch einen DAG (Directed Acyclic Graph) inklusive Lineage.
Vorteile:
- klare Build-Reihenfolge und Abhängigkeiten
- bessere Übersicht bei großen Projekten
- leichteres Debugging
- Änderungen sind review- und deploybar (z. B. per PR)
- Model- und Column-Level Lineage
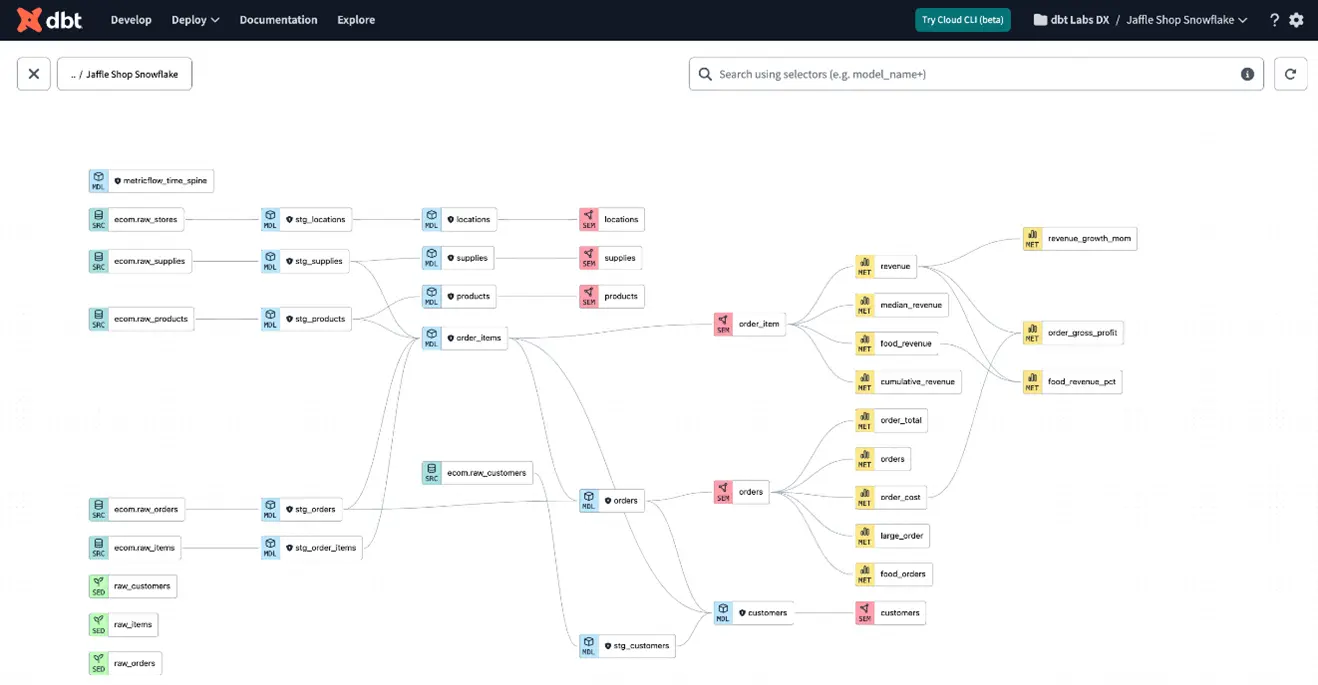
Beispielbild für DAG in der Cloud UI mit Column-Level Lineage (Abbildung 3):
Sources & Freshness
Über source() werden Rohdaten explizit als Inputs beschrieben. Dadurch wird transparent:
- woher Daten stammen,
- welche externen Systeme/Teams verantwortlich sind,
- was „Input“ vs. „eigene Transformationslogik“ ist.
Auf dieser Basis lassen sich Freshness-Checks konfigurieren (z. B. ob ein täglicher Load eingetroffen ist). Das ermöglicht frühzeitige Warnungen bei Liefer- oder Datenqualitätsproblemen und verbessert Governance und Ownership.
Materializations (view / table / incremental / ephemeral)
Materializations bestimmen, wie dbt ein Model auf der Datenbank definiert ist. Das spielt eine große Rolle für Laufzeit und Kosten.
- view: Wird bei jeder Abfrage ausgeführt, ideal für Staging oder kleine Models, bei großen Datenmengen langsam
- table: Persistent, oft schneller bei Abfragen, speichert Daten dauerhaft, gut für Reporting-Tabellen
- incremental: Lädt nur neue/aktualisierte Daten, sehr effizient bei großen Datenmengen
- ephemeral: Nicht materialisiert, wird als Common Table Expression (CTE) in das Ziel-SQL eingefügt.
Tests und Data Quality als Teil des Deployments
dbt bringt generische Tests wie not_null, unique, relationships und accepted_values mit. Zusätzlich kannst du eigene SQL-Tests für fachliche Regeln definieren. Tests lassen sich u. a. auf Models, Spalten, Sources, Snapshots und Seeds anwenden.
Projekt-Dokumentation
dbt kann aus Models, Tests und YAML-Konfigurationen automatisch eine Projekt-Dokumentation erstellen. Typischerweise entstehen dabei u. a.:
- manifest.json (Ressourcen, Konfigurationen, kompiliertes SQL, Abhängigkeiten)
- catalog.json (Metadaten aus dem Warehouse: Tabellen, Spalten, Datentypen)
Damit erhält man eine zentrale, durchsuchbare Übersicht über das gesamte Projekt.
Snapshots
Mit Snapshots lassen sich Änderungen über die Zeit erfassen. Frühere Zustände werden gespeichert, sodass du nachvollziehen kannst, wie sich Werte historisch verändert haben (z. B. bei Slowly Changing Dimensions).
Effizienz durch Makros
Makros helfen, Projekte konsistent zu skalieren: weniger Wiederholungen, weniger Inkonsistenzen, weniger Review-Aufwand. Ein Beispiel aus der Praxis sind dbt-Packages wie AutomateDV (Open Source), die Standardaufgaben im Data-Vault-Umfeld unterstützen – z. B. Hash Keys, generierte Model-Strukturen und Regressionstests.
Metadaten: Artifacts
dbt erzeugt bei Runs standardisierte Artifacts (JSON-Dateien), die den Projektzustand dokumentieren: Models, Sources, Tests, Abhängigkeiten, Laufzeiten etc. Diese Metadaten sind ideal für Lineage-Analysen, Monitoring oder automatisierte Dokumentation.
Wichtige Artifacts:
- manifest.json – vollständige Repräsentation der Projektressourcen (Models, Tests, Makros etc.)
- run_results.json – Ergebnisdetails eines Runs (Laufzeiten, Fehler, Status)
- catalog.json – Warehouse-Metadaten nach Ausführung (Tabellen, Spalten, Datentypen)
Je nach Setup/Features können weitere Artefakte hinzukommen (z. B. rund um Sources/Freshness oder semantische Schichten).
dbt im Vergleich zu ähnlichen Technologien
Im Folgenden werden dbt, Matillion und Talend gegenübergestellt, um einen groben Überblick über Stärken und Schwerpunkte zu geben. Die Tools verfolgen unterschiedliche Philosophien, werden in der Praxis aber häufig im gleichen Umfeld diskutiert.
| Kriterium | dbt | Matillion | Talend |
| Primärer Fokus | Transformation im DWH (kein Ingestion-Kern) | Cloud-ETL/ELT mit UI, DWH-orientiert, Dateningestion Components | Breite Datenintegration (ETL/ELT/APIs) |
| Entwicklungsstil | Code-first (SQL, Jinja), UI | UI-first (Jobs/Components), Low/High-Code | UI-first (Jobs/Components), Low/High-Code |
| Tests & Quality | Vordefinierte Tests, Custom SQL Tests, Freshness-Checks | i. d. R. eher über SQL/Checks/Monitoring, abhängig vom Setup | Data-Quality-Komponenten + Custom Checks, abhängig vom Setup |
| Lineage | Model-DAG + Lineage | Job-/Component-Flows | Job-/Component-Flows |
| Doku | Auto-Doku + Artifacts | Job-Definition, Logs, Monitoring | Job-Definition, Logs, Monitoring |
| Versionierung | Git-first, Branches, PRs, CI/CD | Git möglich, aber UI-geführt und eingeschränkt | Git/SVN möglich, oft komplexer im Prozess |
| Stärken | Transparenz, Reviewbarkeit, CI/CD, Konsistenz in SQL | schneller Einstieg via UI, viele Konnektoren | Enterprise-Integrationsbreite, Konnektivität |
Deployment von dbt und unterstützte Data-Warehouse-Technologien
dbt folgt dem Pushdown-Ansatz: SQL läuft im Ziel-Warehouse, und dbt steuert Build, Abhängigkeiten und Metadaten. dbt unterstützt eine breite Palette moderner Warehouses, z. B. Snowflake, BigQuery, Redshift, Databricks u. a. Dadurch können Teams relativ warehouse-unabhängig entwickeln und profitieren gleichzeitig von Performance und Skalierung der jeweiligen Engine. Dabei muss jedoch beachtet werden, dass der jeweilige Warehouse-Dialekt eingehalten wird, da das SQL an das Warehouse weitergereicht wird.
Einschub: dbt + Data Vault – warum das gut zusammenpassen kann
Data Vault trennt typischerweise in Raw Vault (Hubs, Links, Satellites), Business Vault (Regeln, Harmonisierung) und Data Marts. dbt passt gut dazu, weil Data-Vault-Strukturen schnell komplex werden und ohne gute Tooling-Unterstützung schwer beherrschbar sind.
Hier spielen dbt-Stärken besonders aus:
- DAG/Lineage macht Abhängigkeiten und Build-Reihenfolgen sichtbar
- Packages (z. B. AutomateDV) reduzieren Standardarbeit
- Tests sichern Integrität systematisch ab
- Git-basierte Versionierung unterstützt große Teams mit nachvollziehbaren Änderungen
Fazit
dbt fokussiert sich auf Daten-Transformationen im Zielsystem. Die größten Stärken liegen im SQL-first-Ansatz, der engen Verzahnung mit Software-Engineering-Prinzipien (Git, CI/CD, Tests) und der transparenten Abbildung von Abhängigkeiten über den DAG. Gerade in modernen Cloud-Warehouse-Architekturen und bei komplexen Modellierungsansätzen wie Data Vault entfaltet dbt sein Potenzial durch Governance, Wartbarkeit und Reviewbarkeit.
Aufgaben wie API-Anbindungen, File-Handling, Streaming oder das Steuern beliebiger technischer Workflows gehören nicht zum Kern von dbt und werden typischerweise durch zusätzliche Tools (klassische ETL/ELT-Plattformen oder Orchestratoren wie z. B. Airflow) ergänzt. Teams ohne solide SQL-Kenntnisse oder ohne etablierten Git-/Deployment-Prozess können dbt als weniger attraktiv empfinden. Auch ein übermäßiger Makro-Einsatz kann zu unnötiger Abstraktion führen.
Unterm Strich: dbt ist kein Ersatz für eine vollständige ETL-Plattform, sondern eine spezialisierte Lösung für qualitativ hochwertige Transformationen und analytische Datenprodukte im Data Warehouse.















