
Stable Diffusion – Ein Blick unter die Haube moderner Bildgenerierung

Künstliche Intelligenz hat sich in den letzten Jahren von einem experimentellen Forschungsfeld zu einem zentralen Innovationstreiber in der digitalen Transformation entwickelt. Insbesondere im Bereich der generativen Modelle eröffnen sich neue Möglichkeiten, Inhalte automatisiert zu erstellen, Prozesse zu optimieren und kreative Workflows neu zu definieren.
Ein herausragendes Beispiel dieser Entwicklung ist Stable Diffusion – ein leistungsfähiges Text-zu-Bild-Modell, also KI-Bildgenerierung, das auf modernen Deep-Learning-Architekturen basiert und in der Lage ist, aus natürlichen Spracheingaben visuell kohärente und hochdetaillierte Bilder zu generieren.
Doch hinter dieser scheinbar intuitiven Benutzererfahrung verbirgt sich ein hochkomplexer technischer Stack:
von stochastischen Diffusionsprozessen über latente Repräsentationen bis hin zu multimodalen Embedding-Systemen.
Stable Diffusion nutzt dabei einen probabilistischen Ansatz, bei dem Bildinformationen schrittweise aus zufälligem Rauschen rekonstruiert werden. Dieser Prozess kombiniert mehrere Schlüsseltechnologien, darunter neuronale Netzwerke, Variational Autoencoder (VAE) sowie Transformer-basierte Textencoder, um eine präzise Steuerung der Bildgenerierung zu ermöglichen.
Ziel dieses Beitrags ist es, einen fundierten Einblick in die zugrunde liegenden Mechanismen zu geben und die technischen Prinzipien hinter Stable Diffusion verständlich aufzubereiten. Dabei wird insbesondere auf den Diffusionsprozess, die Rolle des latenten Raums sowie die Integration von Texteingaben in den Generierungsprozess eingegangen.
Grundprinzip: Diffusion statt direkter Generierung
Im Gegensatz zu klassischen generativen Modellen, die versuchen, Daten direkt zu erzeugen (z. B. GANs), verfolgt Stable Diffusion einen indirekten, probabilistischen Ansatz. Statt ein Bild “aus dem Nichts” zu generieren, basiert das Verfahren auf einem sogenannten Diffusionsprozess, bei dem Struktur schrittweise aus Zufall entsteht.
Dieser Ansatz gehört zur Klasse der Denoising Diffusion Probabilistic Models (DDPMs) und lässt sich in zwei klar getrennte Phasen unterteilen: den Forward Process (Training) und den Reverse Process (Inference).
Forward Process: Systematische Zerstörung von Information
Im Forward Process wird ein Trainingsbild über mehrere Schritte hinweg gezielt mit Gaußschem Rauschen überlagert.
Formal bedeutet das:
- In jedem Schritt wird dem Bild ein kleiner Anteil an Noise hinzugefügt
- Nach ausreichend vielen Schritten konvergiert das Bild gegen eine Normalverteilung
Das Resultat:
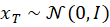
Das ursprüngliche Bild ist dann vollständig “vergessen” – übrig bleibt reines, unstrukturiertes Rauschen.
Dieser Prozess ist deterministisch definiert, da die Noise-Zugabe durch einen festen Zeitplan (Noise Schedule) gesteuert wird. Typischerweise handelt es sich dabei um eine Sequenz von Varianzen βₜ, die festlegen, wie stark das Signal pro Schritt degradiert wird.
Wichtiger Punkt:
Das Modell lernt diesen Prozess nicht – er ist vorgegeben. Er dient ausschließlich dazu, Trainingsdaten in einen Zustand maximaler Entropie zu überführen.
Reverse Process: Rekonstruktion aus Rauschen
Der eigentliche “intelligente” Teil liegt im Reverse Process.
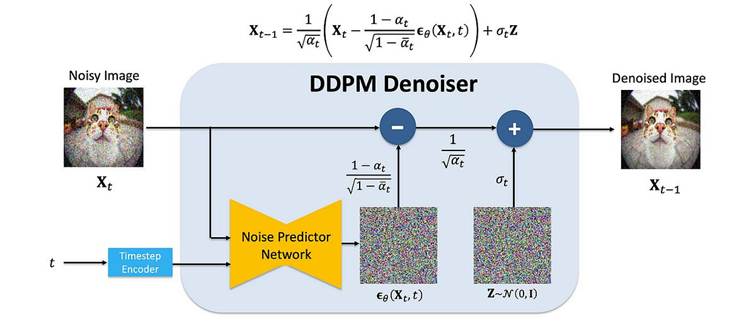
Hier wird ein neuronales Netzwerk (in Stable Diffusion: eine UNet-Architektur) darauf trainiert, den vorher hinzugefügten Noise wieder zu entfernen.
Das Modell approximiert dabei:
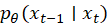
Also die Wahrscheinlichkeit, aus einem verrauschten Zustand den vorherigen Zustand zu rekonstruieren.
In der Praxis bedeutet das:
- Das Modell bekommt ein verrauschtes Bild
- Es sagt voraus, welcher Anteil davon Noise ist
- Dieser Noise wird subtrahiert
- Der Prozess wird iterativ wiederholt
Nach genügend Schritten entsteht wieder ein strukturiertes Bild.
Zu beachten ist dabei:
Das Modell generiert nicht “direkt ein Bild”, sondern führt eine sequenzielle Approximation eines inversen stochastischen Prozesses durch.
Warum funktioniert das?
Der Schlüssel liegt darin, dass das Modell während des Trainings lernt, lokale Strukturen im Rauschen zu erkennen und zu rekonstruieren.
Da der Forward Process kontrolliert ist, kennt man zu jedem Zeitpunkt:
- das ursprüngliche Bild
- den verrauschten Zustand
- den exakt hinzugefügten Noise
Das Trainingsziel ist daher meist:
𝓛 = 𝔼₍ₓ₀,ε,ₜ₎ [ ‖ ε − εθ(xₜ, t) ‖² ]
Das bedeutet: Das Modell lernt, den tatsächlich hinzugefügten Noise möglichst genau vorherzusagen.
Das ist effizienter als direkt das Bild zu rekonstruieren, da Noise statistisch einfacher zu modellieren ist als komplexe Bildverteilungen.
Stochastik und Kontrolle
Ein entscheidender Vorteil dieses Ansatzes ist die Kombination aus:
- Stochastik (zufälliger Startzustand → Vielfalt der Ergebnisse)
- Kontrolle (gezielte Steuerung durch Modell und Parameter)
Der initiale Noise fungiert dabei als Ausgangspunkt für die Generierung.
Unterschiedliche Seeds führen zu unterschiedlichen Bildvarianten, selbst bei identischem Prompt.
Gleichzeitig sorgt der iterative Denoising-Prozess dafür, dass:
- globale Strukturen (z. B. Komposition) früh entstehen
- Details (z. B. Texturen) erst in späteren Schritten ausgearbeitet werden
Intuition: Struktur im Chaos finden
Eine hilfreiche Denkweise ist:
Stable Diffusion erzeugt keine Bilder – es findet Bilder im Rauschen.
Der Trainingsprozess bringt dem Modell bei, welche Muster in zufälligen Strukturen “Sinn ergeben” und wie diese in Richtung realistischer oder stilisierter Bilder transformiert werden können.
Damit wird aus reinem Zufall schrittweise ein kohärentes visuelles Ergebnis – gesteuert durch Wahrscheinlichkeiten, Trainingsdaten und mathematische Optimierung.
Latent Diffusion: Warum Stable Diffusion effizient ist
Ein zentraler Innovationsfaktor von Stable Diffusion liegt nicht nur im Diffusionsprozess selbst, sondern vor allem darin, wo dieser Prozess stattfindet.
Frühere Diffusionsmodelle arbeiteten direkt im Pixelraum hochauflösender Bilder. Das bedeutet, dass jeder einzelne Denoising-Schritt auf Millionen von Pixelwerten operieren musste – mit entsprechend hohem Rechen- und Speicheraufwand.
Stable Diffusion verfolgt stattdessen einen deutlich effizienteren Ansatz: die Durchführung des Diffusionsprozesses im sogenannten Latent Space. Das bedeutet also folgendes:
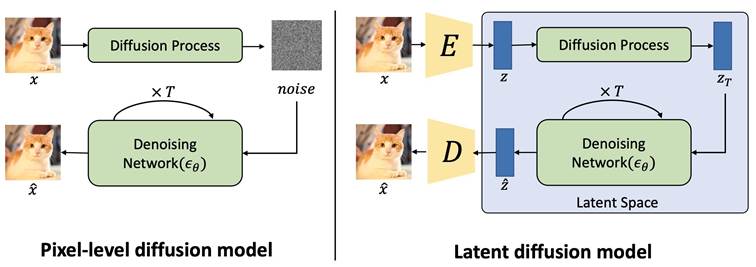
Was ist der Latent Space?
Der Latent Space ist eine komprimierte, abstrakte Repräsentation von Bildinformationen.
Anstatt ein Bild direkt als Pixelmatrix (z. B. 1024×1024×3) zu verarbeiten, wird es zunächst durch einen Variational Autoencoder (VAE) in eine niedrigdimensionale Darstellung überführt.
Typischerweise bedeutet das:
- Originalbild: mehrere Millionen Werte
- Latent Representation: stark reduzierte Dimensionszahl (z. B. Faktor 8–16 kleiner)
Beispielhaft:
Ein 1024×1024 Bild wird auf etwa 128×128 in mehreren Feature-Kanälen komprimiert.
Diese Repräsentation enthält nicht mehr jeden einzelnen Pixel, sondern nur noch die semantisch relevanten Strukturen des Bildes.
Architektur: Zusammenspiel der Komponenten
Stable Diffusion kombiniert drei zentrale Bausteine:
- Variational Autoencoder (VAE)
- Encoder:
Transformiert ein Bild in den Latent Space
- Decoder:
Rekonstruiert aus dem Latent wieder ein Bild
- Encoder:
Der VAE fungiert dabei als eine Art “Informationskompressor”.
- UNet (Denoising Network)
- Operiert ausschließlich im Latent Space
- Entfernt iterativ Noise aus der latenten Repräsentation
- Nutzt Skip-Connections zur Erhaltung von Detailinformationen
Wichtig dabei ist:
Der rechenintensive Diffusionsprozess findet nicht auf Pixeln, sondern auf dieser komprimierten Darstellung statt.
- Text-Conditioning (CLIP / Text Encoder)
- Liefert semantische Steuerungssignale
- Beeinflusst den Denoising-Prozess über Cross-Attention
Effizienzgewinne im Detail
Die Verlagerung in den Latent Space bringt mehrere entscheidende Vorteile:
Reduzierter Rechenaufwand
Da die Datenmenge drastisch reduziert ist, sinkt die Anzahl der notwendigen Operationen pro Schritt erheblich.
Ergebnis:
- Schnellere Inference
- Mehr Iterationen in gleicher Zeit möglich
Geringerer VRAM-Verbrauch
Die Arbeit im Latent Space reduziert den Speicherbedarf signifikant.
Praktische Relevanz:
- Hochauflösende Generierung auf Consumer-GPUs (z. B. RTX 4090) wird erst dadurch realistisch.
- Mehr Spielraum für:
- größere Batch Sizes
- zusätzliche Modelle (z. B. LoRAs, ControlNet)
Skalierbarkeit
Latent Diffusion erlaubt es, Modelle effizient auf höhere Auflösungen zu übertragen, ohne dass die Komplexität exponentiell wächst.
Das ist der Grund, warum Workflows wie:
- Initiale Generierung (z. B. 1024px)
- anschließendes Upscaling (2×, 2.5×)
so gut funktionieren.
Informationsverlust vs. Effizienz
Natürlich bringt Kompression auch Herausforderungen mit sich.
Da der VAE nicht verlustfrei arbeitet:
- gehen feine Details im Latent Space teilweise verloren
- Rekonstruktion ist eine Approximation
Das erklärt typische Effekte:
- leicht “weichgezeichnete” Details
- gelegentliche Artefakte bei feinen Strukturen (z. B. Hände, Augen)
Diese werden oft durch:
- Upscaling
- zusätzliche Sampling-Schritte
- oder spezialisierte Modelle (LoRAs)
ausgeglichen.
Warum das Ganze funktioniert
Der entscheidende Punkt ist:
Für die Bildgenerierung sind nicht alle Pixel gleich wichtig – sondern die zugrunde liegende Struktur.
Der Latent Space filtert irrelevante Details heraus und konzentriert sich auf:
- Formen
- Komposition
- semantische Inhalte
Das Diffusionsmodell arbeitet somit auf einer Ebene, die näher an menschlicher Wahrnehmung liegt als rohe Pixelwerte.
Intuition: Arbeiten auf der “Bedeutungsebene”
Man kann sich den Unterschied so vorstellen:
- Pixelraum:
“Welche Farbe hat dieses einzelne Pixel?” - Latent Space:
“Welche Struktur beschreibt dieses Bild insgesamt?”
Stable Diffusion operiert primär auf dieser zweiten Ebene und kann dadurch deutlich effizienter komplexe visuelle Konzepte erzeugen.
Der eigentliche Sampling-Prozess
Nachdem das Modell trainiert wurde, beginnt in der Praxis der eigentliche Generierungsprozess – das sogenannte Sampling. Hier wird aus reinem Zufallsrauschen schrittweise ein kohärentes Bild erzeugt.
Der Sampling-Prozess ist dabei nichts anderes als die numerische Approximation des Reverse Diffusion Prozesses.
Startpunkt: Reines Rauschen
Jede Generierung beginnt mit einem zufälligen Tensor:
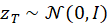
Dieser Zustand enthält keinerlei Struktur – lediglich statistisch verteiltes Rauschen.
Der sogenannte Seed bestimmt dabei den initialen Noise-Zustand und sorgt für Reproduzierbarkeit.
Gleicher Seed + gleiche Parameter = identisches Ergebnis
Iteratives Denoising
Der Kern des Sampling-Prozesses ist eine iterative Schleife über mehrere Zeitschritte :
Für jeden Schritt passiert:
- Das aktuelle Latent wird dem UNet übergeben
- Das Modell schätzt den enthaltenen Noise-Anteil εθ(zₜ,t)
- Der Noise wird (abhängig vom Sampler) entfernt
- Es entsteht ein leicht weniger verrauschtes Latent
Dieser Prozess wird typischerweise 20 bis 50 Mal wiederholt.
Das heisst also, dass dabei zu beachten ist:
Frühe Schritte bestimmen die globale Komposition, späte Schritte verfeinern Details und Texturen.
Sampler: Numerische Integrationsverfahren
Die verschiedenen “Sampler”, die man in Tools wie A1111 oder SwarmUI auswählt, sind im Kern unterschiedliche Lösungsverfahren für stochastische Differentialgleichungen.
Sie bestimmen:
- wie aggressiv Noise entfernt wird
- wie stabil der Prozess ist
- wie viele Schritte benötigt werden
Typische Sampler:
- Euler
- Schnell, stabil
- Gute Allround-Ergebnisse
- Euler a (Ancestral)
- Fügt kontrolliert neue Stochastik hinzu
- Mehr Variation, oft “kreativere” Outputs
- DDIM
- Deterministischer Ansatz
- Schnell, aber manchmal weniger detailreich
- DPM++ (verschiedene Varianten)
- Höhere Präzision
- Bessere Detailerhaltung bei weniger Steps
In der Praxis ist die Wahl des Samplers ein Trade-off zwischen:
- Geschwindigkeit
- Detailgrad
- Konsistenz
Steps: Qualität vs. Effizienz
Die Anzahl der Sampling-Schritte beeinflusst direkt die Qualität:
- Wenige Steps (10–20):
- Schnell
- Oft grobere Ergebnisse
- Mittlere Steps (20–40):
- Gute Balance (typischer Sweet Spot)
- Viele Steps (50+):
- Minimal bessere Details
- Abnehmender Mehrwert (Diminishing Returns)
Wichtig für die Praxis:
Mehr Steps bedeuten nicht automatisch bessere Bilder – ab einem gewissen Punkt stabilisiert sich das Ergebnis.
Guidance: Steuerung durch den Prompt
Während des Samplings wird der Prozess durch den Prompt beeinflusst – über die sogenannte Classifier-Free Guidance (CFG).
Das Modell führt intern zwei Vorhersagen durch:
- Mit Prompt (konditioniert)
- Ohne Prompt (unkonditioniert)
Diese werden kombiniert:
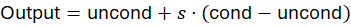
= CFG Scale
Das heisst:
- Niedrig (z. B. 3–5):
Mehr kreative Freiheit, weniger Prompt-Treue - Mittel (7–10):
Standardbereich - Hoch (12+):
Sehr promptgetreu, aber Risiko von Artefakten
Intuition: Vom Groben zum Feinen
Der Sampling-Prozess folgt einer klaren Hierarchie:
- Frühe Schritte:
Layout, Perspektive, grobe Formen - Mittlere Schritte:
Objekte, Anatomie, Komposition - Späte Schritte:
Texturen, Details, Schärfe
Deshalb funktionieren auch Techniken wie:
- High-Res Fix
- Latent Upscaling
so gut: Sie greifen gezielt in spätere Phasen ein.
Text → Bild: Conditioning über CLIP
Stable Diffusion generiert Bilder nicht isoliert, sondern wird durch Text gesteuert. Dieser Prozess wird als Conditioning bezeichnet und ist entscheidend für die Kontrolle der Bildinhalte.
Vom Prompt zum Embedding
Ein eingegebener Textprompt durchläuft mehrere Schritte:
- Tokenisierung
- Zerlegung des Texts in einzelne Tokens (Wörter / Subwörter)
- Text-Encoding
- Verarbeitung durch ein neuronales Netzwerk (meist CLIP Text Encoder)
- Embedding-Erzeugung
- Ausgabe ist ein hochdimensionaler Vektor, der die semantische Bedeutung des Prompts repräsentiert
Dieser Vektor ist die “Maschinensprache” des Modells.
Was ist CLIP?
CLIP (Contrastive Language–Image Pretraining) ist ein multimodales Modell, das darauf trainiert wurde, Text und Bilder in denselben semantischen Raum zu projizieren.
Das bedeutet:
- Ähnliche Texte → ähnliche Vektoren
- Passende Bilder → ähnliche Vektoren
Ergebnis:
Das Modell versteht nicht Wörter, sondern Bedeutungsräume.
Integration in den Diffusionsprozess
Das Text-Embedding wird während des Samplings kontinuierlich in den UNet eingespeist – über sogenannte Cross-Attention Mechanismen.
Das bedeutet konkret:
- Das Modell “vergleicht” Bildstrukturen mit Textinformationen
- Relevante Features werden verstärkt
- Irrelevante werden unterdrückt
Beispiel:
Prompt: “a warrior in heavy armor” → Das Modell sucht im Noise gezielt nach Strukturen, die zu “Rüstung”, “Figur”, etc. passen.
Prompt Engineering als Steuerungsinstrument
Da das Modell auf Embeddings basiert, reagieren kleine Änderungen im Prompt oft stark:
- Reihenfolge von Begriffen kann Einfluss haben
- Gewichtungen (z. B. (keyword:1.3)) verändern Prioritäten
- Negative Prompts unterdrücken unerwünschte Features
Wichtig dabei ist:
Das Modell interpretiert den Prompt nicht linguistisch korrekt, sondern statistisch.
Grenzen des Conditionings
Trotz der Leistungsfähigkeit gibt es Einschränkungen:
- Mehrdeutige Prompts → instabile Ergebnisse
- Zu viele Konzepte → “Verwässerung”
- Konfliktierende Begriffe → Artefakte
Der Grund dafür ist:
Das Modell versucht, mehrere semantische Signale gleichzeitig im selben Bildraum zu erfüllen.
Intuition: Semantische Navigation im Rauschen
Eine hilfreiche Perspektive ist:
- Der Prompt gibt dem Modell keine exakte Anweisung – sondern eine Richtung im semantischen Raum.
Während des Samplings wird das Rauschen so transformiert, dass es sich schrittweise diesem semantischen Ziel annähert.
Einflussparameter (praktisch relevant)
Neben der zugrunde liegenden Modellarchitektur spielen in der praktischen Anwendung von Stable Diffusion eine Reihe von Parametern eine entscheidende Rolle. Diese bestimmen maßgeblich die Qualität, Konsistenz und Steuerbarkeit der generierten Ergebnisse.
Das Verständnis dieser Parameter ist insbesondere in produktiven Umgebungen relevant, in denen reproduzierbare und zielgerichtete Ergebnisse erforderlich sind.
Seed: Reproduzierbarkeit und Variation
Der Seed definiert den initialen Zufallszustand des Noise-Tensors.
Das heisst also:
- Gleicher Seed + gleiche Parameter → identisches Bild
- Unterschiedlicher Seed → neue Variation desselben Prompts
In der Praxis ermöglicht dies:
- gezielte Iteration auf bestehenden Ergebnissen
- kontrollierte Variation bei gleichbleibendem Stil
Das wiederum heisst:
- Wenige Steps:
- schnell, aber weniger detailliert
- Mittlere Steps:
- guter Kompromiss (Standardbereich)
- Viele Steps:
- marginale Detailverbesserung bei deutlich höherem Rechenaufwand
Typischerweise liegt der optimale Bereich zwischen 20 und 40 Schritten, abhängig vom gewählten Sampler.
CFG Scale: Prompt-Treue vs. Kreativität
Die Classifier-Free Guidance Scale (CFG) steuert, wie stark sich das Modell am Prompt orientiert.
Das heisst also:
- Niedrige Werte:
- mehr kreative Freiheit
- geringere Übereinstimmung mit dem Prompt
- Mittlere Werte:
- ausgewogene Ergebnisse
- Hohe Werte:
- sehr promptgetreu
- erhöhtes Risiko für Artefakte und “übersteuerte” Bilder
In der Praxis hat sich ein Bereich von 7 bis 10 als stabiler Standard etabliert.
Auflösung: Detailgrad und Komposition
Die gewählte Bildauflösung beeinflusst sowohl die visuelle Qualität als auch die strukturelle Konsistenz.
Höhere Auflösungen:
- ermöglichen feinere Details
- erhöhen jedoch den Rechen- und Speicherbedarf
Typischer Workflow:
- Generierung in moderater Auflösung
- anschließendes Upscaling (z. B. 2× oder 2.5×)
Dieser Ansatz nutzt die Stärken des Modells effizient aus und vermeidet unnötige Artefakte im initialen Sampling.
Sampler-Auswahl: Charakter des Outputs
Die Wahl des Samplers beeinflusst den “Stil” der Generierung:
- deterministisch vs. stochastisch
- weich vs. kontrastreich
- stabil vs. experimentell
Beispielhafte Auswirkungen:
- Euler a → mehr Variation, oft lebendigere Ergebnisse
- DPM++ → höhere Detailtreue und Konsistenz
Die Samplerwahl ist daher weniger eine “richtige oder falsche” Entscheidung, sondern eine Frage des gewünschten Outputs.
Erweiterte Parameter (optional)
In fortgeschrittenen Workflows kommen zusätzliche Parameter zum Einsatz:
- Denoising Strength (bei img2img / Upscaling)
→ bestimmt, wie stark ein bestehendes Bild verändert wird - Batch Size / Batch Count
→ Parallelisierung von Generierungen - LoRAs / Embeddings
→ gezielte Stil- oder Konzeptsteuerung
Diese erweiterten Optionen ermöglichen eine noch feinere Kontrolle, erhöhen jedoch auch die Komplexität des Workflows.
Intuition: Parameter als Steuerungsvektoren
Die verschiedenen Parameter wirken nicht isoliert, sondern als kombinierte Steuerungsmechanismen innerhalb eines hochdimensionalen Generierungsprozesses.
Das finale Bild ist das Ergebnis eines fein abgestimmten Zusammenspiels aus Zufall, Modellwissen und Parameterkonfiguration.
Fazit
Stable Diffusion ist ein Paradebeispiel dafür, wie moderne KI-Systeme komplexe mathematische Konzepte in praktisch nutzbare Anwendungen überführen.
Statt Bilder direkt zu generieren, basiert das Modell auf einem iterativen Diffusionsprozess, bei dem Struktur schrittweise aus zufälligem Rauschen rekonstruiert wird. Durch die Verlagerung in den Latent Space wird dieser Prozess erheblich effizienter, wodurch hochwertige Bildgenerierung auch auf handelsüblicher Hardware möglich wird.
Die Kombination aus:
- probabilistischem Denoising
- latenter Repräsentation
- textbasierter Steuerung über Embeddings
ermöglicht eine bislang unerreichte Balance aus Kontrolle, Qualität und Flexibilität.
Gleichzeitig zeigt sich in der praktischen Anwendung, dass die Qualität der Ergebnisse nicht allein vom Modell abhängt, sondern maßgeblich durch Parameterwahl und Workflowgestaltung beeinflusst wird.
Stable Diffusion ist damit nicht nur ein Werkzeug zur Bildgenerierung, sondern ein steuerbares System zur strukturierten Transformation von Zufall in visuelle Information.
















