Mit GenAI zur automatisierten Datenverarbeitung

Estimated reading time: 13 Minuten
Einleitung
In der heutigen digitalen Landschaft sehen sich Organisationen oft von Daten überwältigt. Das schiere Volumen, die Geschwindigkeit und die Vielfalt der täglich generierten Informationen stellen eine erhebliche Herausforderung dar. Obwohl diese Daten ein immenses Potenzial für Erkenntnisse und Innovationen bergen, stoßen herkömmliche Verarbeitungsmethoden oft an ihre Grenzen und verursachen Engpässe. Genau hier bietet Generative AI (GenAI) eine transformative Lösung.
GenAI, das sich auf die Erstellung neuer Inhalte wie Text, Bilder oder Code durch das Erlernen von Mustern aus vorhandenen Daten konzentriert, bietet leistungsstarke Werkzeuge zur Automatisierung komplexer Informationsverarbeitung. So kann GenAI durch den Einsatz von Modellen wie Large Language Models (LLMs) Kontext verstehen, Bedeutung extrahieren, Inhalte zusammenfassen und strukturierte Ausgaben aus unstrukturierten Eingaben generieren. Diese Fähigkeit ermöglicht eine beispiellose Effizienz und fördert somit bessere datengesteuerte Entscheidungen.
Dieser Artikel untersucht praktische Anwendungen von GenAI bei der Automatisierung der Informationsverarbeitung. Wir werden zunächst wichtige Anwendungsfälle untersuchen, danach die entscheidende Rolle von MLOps (Machine Learning Operations) für eine zuverlässige Bereitstellung hervorheben, außerdem das Konzept der GenAI Accelerators zur Optimierung der Implementierung vorstellen und schließlich potenzielle Herausforderungen diskutieren, die für eine erfolgreiche Einführung gemeistert werden müssen.
Anwendungsfälle von GenAI in der Informationsverarbeitung
Dank seiner Vielseitigkeit kann GenAI viele verschiedene informationszentrierte Aufgaben in diversen Branchen automatisieren. Hier sind einige überzeugende Beispiele:
1. Automatisierte Schadenklassifizierung und ‑analyse im Versicherungswesen
Versicherungsunternehmen stehen vor der Herausforderung, eine große Anzahl von Schadensmeldungen zu bearbeiten, die häufig mit unstrukturierten Beschreibungen und verschiedenen Dokumenten wie Bildern und PDFs eingereicht werden. Die manuelle Klassifizierung von Schäden, die Bewertung des Schweregrads und die Extraktion von Details ist deshalb arbeitsintensiv und anfällig für Inkonsistenzen. Ein multimodales GenAI-System kann diesen Workflow jedoch erheblich automatisieren.
Der Prozess beginnt typischerweise damit, dass Optical Character Recognition (OCR)-Dienste Text aus gescannten Dokumenten digitalisieren. Anschließend analysieren GenAI-Modelle potenziell feinabgestimmte Foundation Models, auf die über Plattformen wie Amazon Bedrock, Google Vertex AI oder Azure OpenAI Service zugegriffen wird, den extrahierten Text und die zugehörigen Bilder. Diese Modelle führen entscheidende Aufgaben aus, wie z. B. die Klassifizierung der Schadensart (z. B. Kollision, Wasserschaden), die Bewertung von Schweregradindikatoren, die Extraktion von Schlüsselinformationen wie Policennummern und Unfalldaten und sogar die Identifizierung potenziell betrügerischer Ansprüche auf der Grundlage erlernter Muster. Zuletzt werden die extrahierten Informationen automatisch strukturiert, oft in Formate wie JSON.
Wichtig ist hierbei, dass dann Datenvalidierungswerkzeuge angewendet werden, um sicherzustellen, dass diese strukturierten Daten den erforderlichen Geschäftsregeln entsprechen, wie z. B. gültige Datumsformate oder plausible Schadensbeträge, wodurch die Datenintegrität verbessert wird, bevor sie in nachgelagerte Systeme gelangen. Diese Automatisierung führt folglich zu einer schnelleren Schadensbearbeitung, verbesserter Genauigkeit, reduzierten Betriebskosten und erhöhter Kundenzufriedenheit durch schnellere Lösungen.
Herausforderung
Versicherungsunternehmen verarbeiten eine große Anzahl von Schadensmeldungen, die oft mit unstrukturierten Beschreibungen und Belegen (Bilder, PDFs) eingereicht werden. Die manuelle Klassifizierung der Schadensart, die Bewertung des Schweregrads und die Extraktion wichtiger Details ist folglich arbeitsintensiv, langsam und anfällig für Inkonsistenzen.
GenAI-Lösung
Ein multimodales GenAI-System kann diesen Workflow automatisieren.
- Textextraktion: Werkzeuge wie AWS Textract oder ähnliche Optical Character Recognition (OCR)-Dienste können Text aus gescannten Dokumenten und PDFs digitalisieren.
- Informationsextraktion & Klassifizierung: GenAI-Modelle (potenziell feinabgestimmte Foundation Models, auf die über Plattformen wie Amazon Bedrock, Google Vertex AI oder Azure OpenAI Service zugegriffen wird) können den extrahierten Text und die zugehörigen Bilder analysieren. Diese Modelle können die Schadensart klassifizieren (z. B. Kollision, Wasserschaden, Feuer), Schweregradindikatoren bewerten, wichtige Informationen extrahieren (Policennummer, Unfalldatum, beteiligte Parteien) und sogar potenziell betrügerische Ansprüche anhand erlernter Muster identifizieren.
- Datenstrukturierung & Validierung: Die extrahierten Informationen können automatisch strukturiert werden (z. B. im JSON-Format). Datenvalidierungsbibliotheken (wie Pydantic in Python) können nach der Extraktion verwendet werden, um sicherzustellen, dass die strukturierten Daten den erforderlichen Formaten und Geschäftsregeln entsprechen (z. B. gültige Datumsformate, plausible Schadensbeträge) und so die Datenintegrität vor der nachgelagerten Verarbeitung verbessern.
Vorteile
Schnellere Schadensbearbeitung, verbesserte Genauigkeit und Konsistenz bei der Klassifizierung, reduzierte Betriebskosten und erhöhte Kundenzufriedenheit durch schnellere Lösungen. Human-in-the-Loop ist zusätzlich möglich und erleichtert so eine teilweise Automatisierung.
2. Intelligenter Wissensassistent für technische Informationen
Wartungstechniker, Ingenieure und Supportmitarbeiter haben oft Schwierigkeiten, spezifische Informationen zu finden, die in umfangreichen technischen Handbüchern, Standard Operating Procedures (SOPs) oder historischen Reparaturprotokollen vergraben sind. Die manuelle Suche ist ineffizient und kann kritische Aufgaben verzögern.
Ein GenAI-gestützter Wissensassistent, der deshalb typischerweise Retrieval-Augmented Generation (RAG) nutzt, bietet eine effektive Lösung. Der Prozess beginnt mit der Aufnahme relevanter Dokumente, die dann in überschaubare Abschnitte (Chunks) zerlegt und mithilfe eines Embedding-Modells in numerische Darstellungen, sogenannte Embeddings, umgewandelt werden. Diese Embeddings werden anschließend in einer spezialisierten Vektordatenbank gespeichert.
Wenn ein Benutzer eine Frage stellt, wie z. B. „Wie lautet der Schmierplan für Pumpenmodell X?“, wird die Anfrage selbst ebenfalls in ein Embedding umgewandelt. Die Vektordatenbank führt daraufhin eine Ähnlichkeitssuche durch, um die Dokumenten-Chunks zu finden, deren Embeddings dem Anfrage-Embedding am nächsten kommen. Diese relevanten Chunks werden dann zusammen mit der ursprünglichen Anfrage an ein LLM übergeben. Das LLM synthetisiert eine kohärente, kontextbezogene Antwort, die ausschließlich auf den abgerufenen Informationen basiert, was das Risiko der Generierung falscher Informationen, oft als Halluzination bezeichnet, erheblich minimiert.
Zu den Vorteilen gehören somit ein wesentlich schnellerer Zugriff auf genaue Informationen, reduzierte Maschinenausfallzeiten, verbesserte Erstbehebungsraten für Techniker sowie eine bessere Wissenserhaltung und ‑weitergabe innerhalb der Organisation.
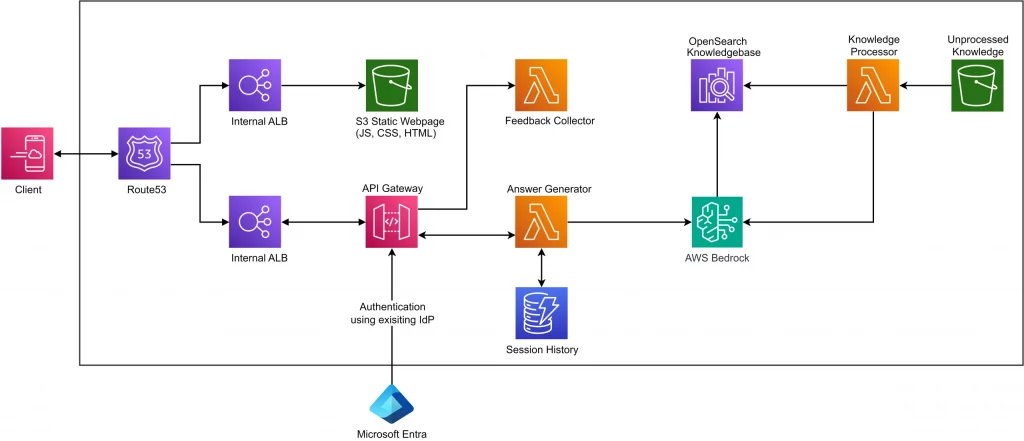
Herausforderung
Wartungstechniker, Ingenieure oder Supportmitarbeiter benötigen oft spezifische Informationen, die in umfangreichen technischen Handbüchern, Standard Operating Procedures (SOPs), historischen Reparaturprotokollen und internen Wissensdatenbanken vergraben sind. Die manuelle Suche ist ineffizient und kann kritische Aufgaben verzögern.
GenAI-Lösung
Ein GenAI-gestützter Wissensassistent, der Retrieval-Augmented Generation (RAG) nutzt.
- Wissensaufnahme: Relevante Dokumente werden aufgenommen, in überschaubare Teile (Chunks) zerlegt und mithilfe eines Embedding-Modells in numerische Darstellungen (Embeddings) umgewandelt. Diese Embeddings werden in einer spezialisierten Vektordatenbank gespeichert.
- Anfrageverarbeitung: Wenn ein Benutzer eine Frage stellt (z. B. „Wie lautet der Schmierplan für Pumpenmodell X?“), wird die Anfrage ebenfalls in ein Embedding umgewandelt.
- Informationsabruf: Die Vektordatenbank führt eine Ähnlichkeitssuche durch, um die Dokumenten-Chunks zu finden, deren Embeddings dem Anfrage-Embedding am nächsten kommen.
- Antwortsynthese: Diese relevanten Chunks werden zusammen mit der ursprünglichen Anfrage an ein LLM übergeben. Das LLM synthetisiert eine kohärente, kontextbezogene Antwort, die ausschließlich auf den abgerufenen Informationen basiert, wodurch das Risiko von Halluzinationen reduziert wird.
Vorteile
Deutlich schnellerer Zugriff auf genaue Informationen, reduzierte Maschinenausfallzeiten, verbesserte Erstbehebungsraten für Techniker, bessere Wissenserhaltung und ‑weitergabe innerhalb der Organisation. Smartphone Apps und Webseiten ermöglichen den Zugriff auf die Informationen direkt an der Maschine.
3. Extrahieren strukturierter Erkenntnisse aus unstrukturiertem Kundenfeedback
Organisationen sammeln immense Mengen an unstrukturiertem Kundenfeedback aus Quellen wie E‑Mails, Support-Tickets, Umfrageantworten, sozialen Medien und Anrufprotokollen. Die manuelle Analyse dieser Daten zur Identifizierung von Trends, Stimmungen und Schlüsselproblemen ist jedoch unglaublich schwierig und selten umfassend. GenAI, insbesondere LLMs, die für fortgeschrittene Natural Language Processing (NLP) konfiguriert sind, kann diese Analyse automatisieren.
Unstrukturierte Textdaten werden dazu in eine LLM-Verarbeitungspipeline eingespeist, wo das Modell aufgefordert wird, verschiedene Aufgaben auszuführen. Diese können Themenklassifizierung (Kategorisierung von Feedback in Themen wie Produktmerkmale oder Kundenservice), Sentimentanalyse (Bestimmung eines positiven, negativen oder neutralen Tons), Extraktion von Schlüsselinformationen (Identifizierung von Entitäten wie Produktnamen oder Standorten), Zusammenfassung (Verdichtung von langem Feedback) und Standardisierung (Umwandlung von Umgangssprache in Standardbegriffe) umfassen.
Die Ergebnisse dieser Analysen werden dann in einem strukturierten Format, wie z. B. JSON-Objekten, ausgegeben und sind bereit für die Aufnahme in Datenbanken, Business-Intelligence-Tools oder CRM-Systeme. Dieser Ansatz liefert folglich ein tieferes Verständnis der Kundenbedürfnisse und Schwachstellen, ermöglicht eine schnellere Identifizierung aufkommender Probleme, verbessert Produktentwicklungszyklen, erlaubt gezieltere Marketingmaßnahmen und automatisiert zuvor manuelle Analyseaufgaben.
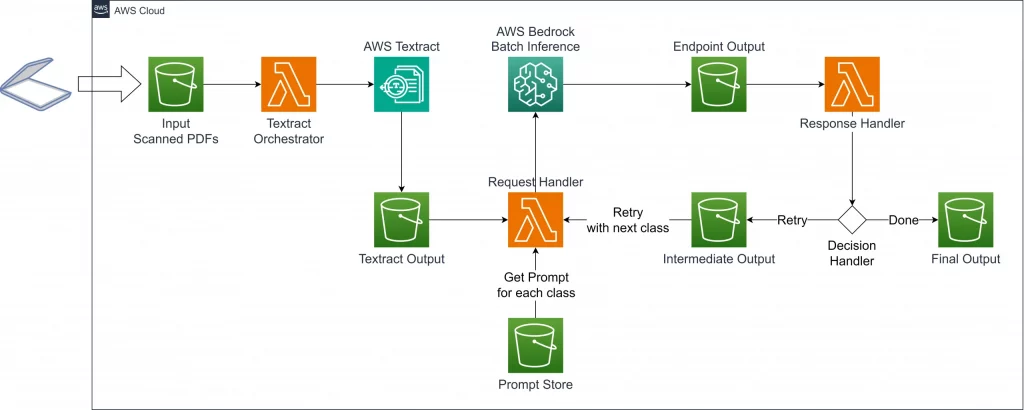
Herausforderung
Organisationen sammeln riesige Mengen an unstrukturiertem Kundenfeedback aus E‑Mails, Support-Tickets, Umfragen (offene Antworten), sozialen Medien und Anrufprotokollen. Die manuelle Analyse dieser Daten zur Identifizierung von Trends, Stimmungen und Schlüsselproblemen ist unglaublich schwierig und wird selten umfassend durchgeführt.
GenAI-Lösung
Einsatz von LLMs für fortgeschrittene Natural Language Processing (NLP).
- Verarbeitungspipeline: Unstrukturierte Textdaten werden in ein LLM eingespeist, das speziell für verschiedene Aufgaben aufgefordert wird.
- Aufgaben: Das LLM kann ausführen:
- Themenklassifizierung: Kategorisieren von Feedback in vordefinierte Themen (z. B. Produktmerkmale, Kundenservice, Abrechnung).
- Sentimentanalyse: Bestimmen von ausgedrücktem Sentiment (positiv, negativ, neutral).
- Extraktion von Schlüsselinformationen: Identifizieren spezifischer Entitäten wie Produktnamen, Standorte oder Beschwerdedetails.
- Zusammenfassung: Verdichten eines langen Feedbacks zu einer prägnanten Zusammenfassung.
- Standardisierung: Umwandeln umgangssprachlicher Ausdrücke in Standardbegriffe.
- Strukturierte Ausgabe: Die Ergebnisse dieser Analysen werden in einem strukturierten Format wie JSON ausgegeben und sind bereit für die Aufnahme in Datenbanken, Business-Intelligence-Tools oder CRM-Systeme.
Vorteile
Tieferes Verständnis der Kundenbedürfnisse und Schwachstellen, schnellere Identifizierung aufkommender Probleme, verbesserte Produktentwicklungszyklen, gezieltere Marketingmaßnahmen und Automatisierung manueller Analyseaufgaben.
Die kritische Rolle von MLOps bei der GenAI-Automatisierung
Die zuverlässige Bereitstellung von GenAI-Modellen in der Produktion und die Aufrechterhaltung ihrer Leistung erfordern einen starken Fokus auf MLOps (Machine Learning Operations). MLOps wendet DevOps-Prinzipien auf den Lebenszyklus des maschinellen Lernens an und gewährleistet dadurch Robustheit, Skalierbarkeit und Vertrauenswürdigkeit, die für komplexe GenAI-Systeme entscheidend sind. Effektives MLOps für GenAI umfasst dabei mehrere Schlüsselbereiche.
Es beginnt mit robustem Datenmanagement und ‑engineering, einschließlich Pipelines für die Handhabung der Daten, die für Training, Feinabstimmung und Evaluierung verwendet werden, sowie der effektiven Verwaltung von Prompts.
Darüber hinaus beinhaltet es die Orchestrierung für Modelltraining und Feinabstimmung. Unabhängig davon, ob das Training von Grund auf durchgeführt wird, oder eine Feinabstimmung vortrainierter Modelle vorgenommen wird, werden alle Experimente verfolgt.
Strenge Modellbewertungs- und Validierungsprozesse sind unerlässlich, wobei relevante Metriken wie Genauigkeit, Flüssigkeit und Bias-Erkennung sowie spezifische Testdatensätze verwendet werden; für RAG-Systeme ist auch die Bewertung der Abrufgenauigkeit entscheidend.
MLOps deckt auch Bereitstellungs- und Servicestrategien ab, um Modelle effizient verfügbar zu machen und Ressourcen entsprechend zu skalieren. Kontinuierliche Überwachungs- und Feedbackmechanismen sind entscheidend für die Verfolgung der Modellleistung in der Produktion, die Erkennung von Problemen wie Data Drift oder Leistungsabfall und die Einbeziehung von Feedback zur kontinuierlichen Verbesserung von trainierten Modellen.
Schließlich sind starke Governance- und Sicherheitspraktiken erforderlich, um Compliance sicherzustellen, den Zugriff zu verwalten, Assets zu sichern und Audit-Trails zu pflegen. MLOps bietet die notwendige Disziplin und die Werkzeuge, um Komplexität zu managen, Vertrauenswürdigkeit zu gewährleisten und die kontinuierliche Verbesserung zu ermöglichen, die für diese leistungsstarken GenAI-Systeme unerlässlich ist.
Schlüsselkomponenten
Schlüsselkomponenten eines MLOps-Frameworks für GenAI umfassen:
- Datenmanagement & Engineering: Pipelines zur Aufnahme, Bereinigung, Transformation und Versionierung der Daten, die für das Training, die Feinabstimmung und die Evaluierung von GenAI-Modellen verwendet werden. Dies beinhaltet die Verwaltung von Prompts und potenziell annotierten Daten für überwachte Feinabstimmung.
- Modelltraining & Feinabstimmungs-Orchestrierung: Automatisierte Workflows für das Training von Modellen von Grund auf (weniger verbreitet bei großen Foundation Models) oder, typischerweise, die Feinabstimmung vortrainierter Modelle auf domänenspezifische Daten. Dies beinhaltet Experimentverfolgung und Modellversionierung.
- Modellbewertung & Validierung: Strenge Prozesse zur Bewertung der Modellleistung anhand relevanter Metriken (Genauigkeit, Flüssigkeit, Kohärenz, Toxizität, Bias-Erkennung) und spezifischer Testdatensätze vor der Bereitstellung. Für RAG-Systeme ist auch die Bewertung der Abrufgenauigkeit entscheidend.
- Bereitstellung & Serving: Strategien zur effizienten Bereitstellung von Modellen (z. B. API-Endpunkte, Stapelverarbeitung) und Skalierung von Ressourcen je nach Bedarf.
- Überwachung & Feedback: Kontinuierliche Überwachung der Modellleistung in der Produktion zur Erkennung von Problemen wie:
- Data Drift: Änderungen in der Verteilung der Eingabedaten im Vergleich zu den Trainingsdaten.
- Concept Drift: Änderungen in den zugrunde liegenden Beziehungen, die das Modell gelernt hat.
- Leistungsabfall: Abnahme der Genauigkeit, erhöhte Latenz oder Anstieg schädlicher Ausgaben.
- Feedback-Schleife: Mechanismen zur Sammlung von Benutzerfeedback und problematischen Ausgaben, um Umschulungs- oder Feinabstimmungszyklen zu informieren.
- Governance & Sicherheit: Gewährleistung von Compliance, Verwaltung von Zugriffskontrollen, Sicherung von Modellartefakten und Daten sowie Pflege von Audit-Trails.
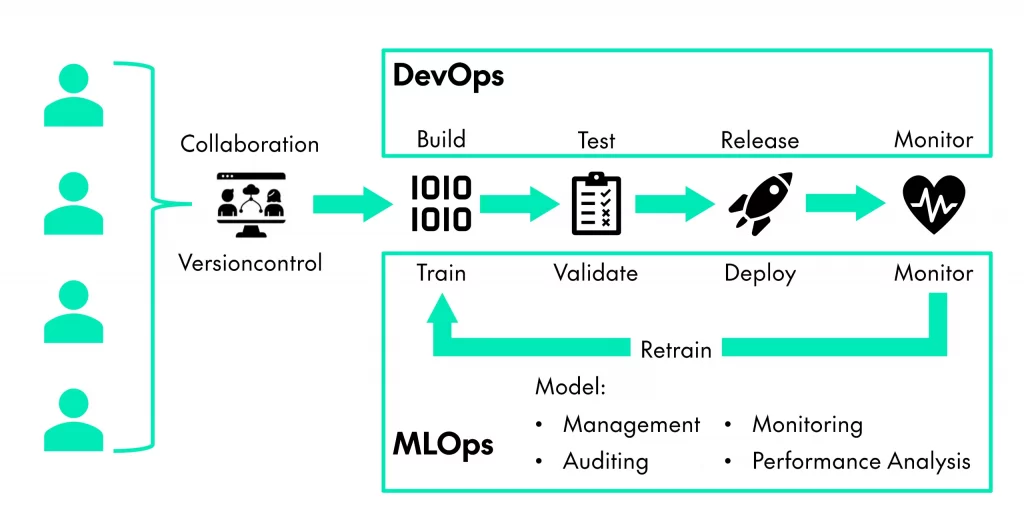
MLOps ist also für die GenAI-Automatisierung unerlässlich, da es die Disziplin und die Werkzeuge bereitstellt, die erforderlich sind, um die Komplexität zu managen, Vertrauenswürdigkeit zu gewährleisten und die kontinuierliche Verbesserung dieser leistungsstarken, aber dynamischen Systeme zu ermöglichen.
GenAI Accelerator: Optimierung der Implementierung
In Anbetracht der damit verbundenen Komplexität hat sich das Konzept eines „GenAI Accelerator“ – einer Sammlung vorgefertigter Komponenten, Best Practices und Infrastrukturvorlagen – herauskristallisiert, um Organisationen den Start ihrer GenAI-Initiativen zu erleichtern. Obwohl sich spezifische Angebote unterscheiden, kann ein typischer GenAI Accelerator beispielsweise bieten:
- Wiederverwendbare Module: Vorgefertigter Code oder Dienste für gängige Aufgaben wie Datenaufnahme für RAG, Prompt-Engineering-Frameworks, Interaktionsschichten (Chat-Schnittstellen) und Konnektoren zu gängigen LLMs und Vektordatenbanken.
- Infrastructure as Code (IaC): Vorlagen (z. B. Terraform, CloudFormation) zur schnellen Bereitstellung der notwendigen Cloud-Infrastruktur (Rechenleistung, Speicher, Netzwerk, verwaltete KI-Dienste) bei großen Anbietern wie AWS, Azure oder GCP.
- Referenzarchitekturen: Bewährte Blaupausen für gängige Anwendungsfälle (wie die oben beschriebenen). Diese können angepasst werden und sind in Konzept- und Integrationsphasen gleichermaßen hilfreich.
- MLOps-Integration: Vorkonfigurierte MLOps-Pipelines oder Integrationen mit MLOps-Plattformen, die auf GenAI-Workflows zugeschnitten sind.
- Best Practices & Richtlinien: Dokumentation zur Datenauswahl für Wissensdatenbanken, Prompt-Design, Sicherheitsüberlegungen und verantwortungsvolle KI-Praktiken.
- Monitoring-Dashboards: Vorgefertigte Dashboards zur Verfolgung von Key Performance Indicators (KPIs), Kosten und Modellverhalten.
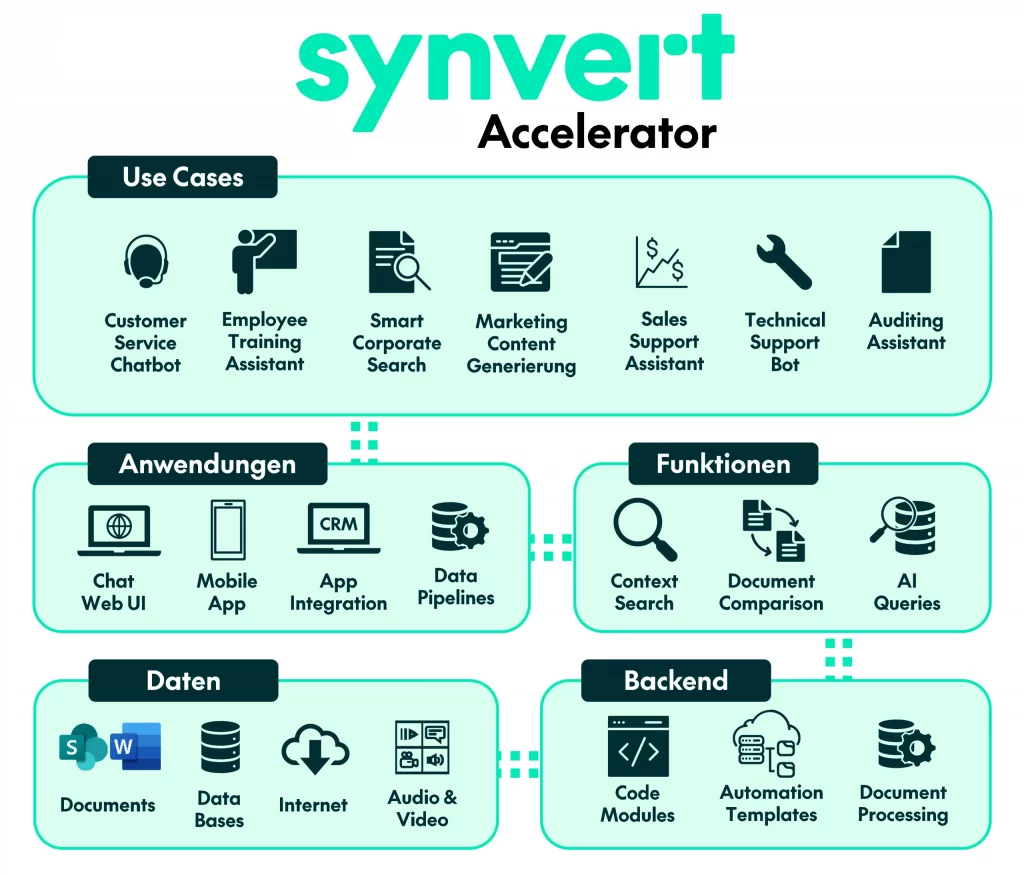
Die Verwendung eines solchen Accelerators kann die Entwicklungszeit erheblich verkürzen, zudem Implementierungsrisiken senken und Konsistenz sowie Best Practices bei GenAI-Projekten innerhalb einer Organisation durchsetzen.
Bewältigung potenzieller Fallstricke bei der GenAI-Implementierung
Obwohl das Potenzial von GenAI immens ist, müssen sich Organisationen potenzieller Herausforderungen bewusst sein und diese proaktiv angehen:
- Datenqualität und Bias: GenAI-Modelle sind grundlegend datengesteuert. Folglich kann schlechte Qualität, unvollständige oder verzerrte Trainingsdaten zu ungenauen, unfairen oder unsinnigen Ausgaben führen. Rigorose Datenkuration und Bias-Erkennung sind daher unerlässlich. Bei RAG ist überdies die Qualität und Relevanz der Wissensdatenbank von größter Bedeutung.
- Modell-Halluzinationen: LLMs können manchmal plausibel klingende, aber sachlich falsche oder erfundene Informationen („Halluzinationen“) generieren. Zu den Minderungsstrategien gehören das Grounding von Modellen mit abgerufenen Daten (RAG), die Implementierung von Validierungsprüfungen, Prompt-Engineering-Techniken und die Einstellung geeigneter Temperatur-/Kreativitätsniveaus. Auch ein Wechsel der Modellreihe kann hier hilfreich sein.
- Sicherheit und Datenschutz: Der Umgang mit sensiblen Daten erfordert robuste Sicherheitsmaßnahmen, einschließlich Datenverschlüsselung, Zugriffskontrollen, Eingabe-/Ausgabeprüfung zur Verhinderung von Prompt-Injection-Angriffen und die Sicherstellung der Einhaltung von Datenschutzbestimmungen (wie GDPR, CCPA). Gegebenenfalls könnte Anonymisierung oder Pseudonymisierung nötig sein.
- Ethische Überlegungen: Fragen zu Fairness, Transparenz, Rechenschaftspflicht und potenziellem Missbrauch (z. B. Erstellung von Deepfakes oder Fehlinformationen) müssen durch verantwortungsvolle KI-Richtlinien, menschliche Aufsicht und klare Nutzungsrichtlinien angegangen werden.
- Kostenmanagement: Das Training und, noch bedeutender, die Ausführung von Inferenz auf großen GenAI-Modellen kann rechenintensiv sein. Eine sorgfältige Modellauswahl, effiziente Bereitstellungsstrategien (z. B. Quantisierung, optimierte Hardware) und Kostenüberwachung sind entscheidend.
- Integrationskomplexität: Die nahtlose Integration von GenAI-Funktionen in bestehende Geschäftsprozesse und IT-Systeme erfordert sorgfältige Planung, API-Management und potenziell erhebliche Workflow-Neugestaltungen.
- Fachkräftemangel: Eine erfolgreiche Implementierung erfordert Fachwissen in KI/ML, Data Science, Prompt Engineering, MLOps, Cloud-Infrastruktur und Domänenwissen. Organisationen müssen daher eventuell bestehende Teams weiterbilden oder neue Talente einstellen.
Fazit
Generative AI stellt einen Paradigmenwechsel bei der Automatisierung der Informationsverarbeitung dar. Von der Optimierung von Versicherungsansprüchen und der Ausstattung von Technikern mit sofortigem Wissen bis hin zur Gewinnung tiefer Einblicke aus Kundenfeedback sind die Anwendungen vielfältig und transformativ. Indem sie die Leistungsfähigkeit von LLMs und verwandten Technologien nutzen, können Organisationen signifikante Effizienzsteigerungen erzielen, die Entscheidungsfindung verbessern und neue Werte aus ihren Datenbeständen schaffen.
Allerdings erfordert die Realisierung dieses Potenzials einen durchdachten und strategischen Ansatz. Die Implementierung robuster MLOps-Praktiken ist folglich nicht verhandelbar für den Aufbau zuverlässiger und skalierbarer Lösungen. Zusätzlich kann die Nutzung von Frameworks wie GenAI Accelerators die Einführung beschleunigen. Entscheidend ist aber auch, dass die Wachsamkeit gegenüber potenziellen Fallstricken – angefangen bei Datenqualität und Halluzinationen bis hin zu Sicherheit und Ethik – entscheidend für eine verantwortungsvolle und erfolgreiche Implementierung ist. Indem Organisationen GenAI strategisch einsetzen, können sie die Informationsflut effektiv bewältigen und sie in einen leistungsstarken Motor für Wachstum und Innovation verwandeln.