
Migration zu Apache Airflow im DWH
Die Migration zu Apache Airflow beschreibt den laufenden Modernisierungsprozess einer gewachsenen, eigenentwickelten On-Prem-Orchestrierung hin zu einer etablierten, Python-basierten Workflow-Plattform. Während die bestehende servicebasierte Steuerung weiterhin zuverlässig arbeitet, ist sie zunehmend von historisch gewachsenen Konfigurationsstrukturen und manuellen Betriebsabläufen geprägt.
Die aktuelle Orchestrierung läuft als permanenter Service. Sie wird regelmäßig über Cronjobs angestoßen, koordiniert Prozesse über Socket-Kommunikation und steuert Ladeläufe auf Basis von JSON-Definitionen sowie einer zentralen Metadatenbank. Die zugrunde liegenden Programme bestehen aus Python-2-Tools, die aufgrund des offiziellen End-of-Life von Python 2 perspektivisch abgelöst werden müssen.
Obwohl diese Architektur stabil funktioniert, bringt sie über die Jahre technischen Altbestand mit sich, wie verteilte Konfigurationen, komplexe Abhängigkeiten und manuell nachvollziehbare Prozessketten. Gleichzeitig wächst mit der zunehmenden Komplexität der täglichen Ladeprozesse der Bedarf nach einer Plattform, die Transparenz schafft, Wiederholbarkeit ermöglicht und sich flexibel erweitern lässt.
Vor diesem Hintergrund entsteht parallel eine neue Orchestrierungsstruktur auf Basis von Apache Airflow. Ziel der Migration zu Apache Airflow ist es nicht nur, bestehende Technik zu ersetzen, sondern die Steuerungslogik klarer zu modellieren.
Ausgangslage vor der Migration
Das derzeitige System basiert auf einer eigenentwickelten, servicebasierten On-Prem-Orchestrierung.
Der Dispatcher liest JSON-Definitionen ein, prüft Abhängigkeiten in der Metadatenbank und startet anschließend die jeweiligen Verarbeitungsschritte. Er übernimmt damit zugleich Scheduling, Abhängigkeitsauflösung und Statusverwaltung innerhalb des bestehenden Systems.
Die Architektur besteht aus mehreren ineinandergreifenden Schichten. Jobs beinhalten Python-2-Programme, die die Orchestrierungsaufgaben ausführen. JSON-Dateien definieren die Steuerlogik, während die zentrale Metadatenbank Abhängigkeiten, Statuswerte und Ladezyklen verwaltet. Jeder Bestandteil ist in einer separaten JSON-Datei definiert.
Die gesamte Verarbeitung folgt einer klaren Struktur (Abbildung 1):
- Dispatcher initiiert tägliche oder monatliche Ladezyklen.
- Pläne strukturieren die Verarbeitung entlang des Datenmodells (z. B. Anker‑, Versions‑, Dimensionsobjekte).
- Ladegruppen fassen fachlich zusammenhängende Ladeeinheiten zusammen.
- Jobs führen zu orchestrierenden Arbeiten aus, etwa SQL-Operationen und ETL-Workflows.
Obwohl diese Struktur funktional und stabil ist, ist sie historisch gewachsen und entsprechend komplex im Betrieb. Änderungen müssen konsistent an mehreren Stellen vorgenommen und manuell importiert werden. Zudem lässt sich ein vollständiger Überblick über Plan- und Jobabhängigkeiten oft nur über gezielte Datenbankabfragen oder durch manuelle Analyse in den JSON-Dateien gewinnen.

Grenzen der alten Struktur
Mit steigender Komplexität der Ladeprozesse wird deutlich, dass die Dispatcher-basierte Struktur zunehmend an ihre strukturellen Grenzen gelangt. Die enge Verzahnung von laufendem Service, Steuerlogik und Ausführung sorgt zwar für ein konsistentes Gesamtsystem, erhöht jedoch den Aufwand bei strukturellen Anpassungen. Transparenz über Abhängigkeiten und Laufzustände ist grundsätzlich vorhanden, setzt jedoch gezielte Analyse und fundierte Systemkenntnis voraus.
Darüber hinaus steht nur eine eingeschränkte nutzbare GUI zur Verfügung, die ausschließlich unter macOS verfügbar ist.
Hinzu kommt ein technischer Plattformwechsel im On-Prem-Umfeld. Mit der Migration auf RHEL 9 ist Python 2 nicht mehr Bestandteil der Installation. Da die vorhandenen Programme auf Python 2 basieren und Python 2 offiziell End-of-Life ist, entsteht ein konkreter Modernisierungsbedarf. Zudem wächst das DWH sowohl technisch als auch fachlich über das ursprüngliche Designkonzept der Orchestrierung hinaus.
Die Notwendigkeit einer modernen und flexiblen Orchestrierungslösung wird damit deutlich.
Workflows in Apache Airflow - wie Airflow funktioniert
Apache Airflow ist eine Python-basierte Open-Source-Orchestrierungssoftware zur Definition, Planung und Überwachung von Workflows. Sie wird eingesetzt, um komplexe Datenprozesse strukturiert, nachvollziehbar und automatisiert auszuführen. Ein wesentlicher Vorteil von Apache Airflow besteht in der technologieunabhängigen Orchestrierung unterschiedlichster Systeme. Zudem stellt Airflow eine Vielzahl von Operatoren für unterschiedlichste Aufgaben bereit.
Zusätzlich lassen sich eigene Operatoren entwickeln, falls spezielle Anforderungen bestehen. Dadurch lässt sich Airflow flexibel in bestehende Systemlandschaften integrieren und ist nicht auf eine bestimmte Technologie oder Laufzeitumgebung beschränkt.
In Apache Airflow werden Workflows als DAGs (Directed Acyclic Graphs) modelliert. Der DAG beschreibt dabei, welche Schritte ausgeführt werden, in welcher Reihenfolge sie ablaufen und unter welchen Bedingungen sie starten dürfen. DAGs werden direkt als Python-Code definiert und nicht mehr über abstrakte Konfigurationsdateien gesteuert.
Ein DAG legt außerdem fest, wann ein Workflow ausgeführt wird und ab welchem Zeitpunkt er aktiv ist. Dazu gehören insbesondere der Zeitplan (schedule), der frühestmögliche Startzeitpunkt (start_date) sowie die Definition der einzelnen Tasks und deren Abhängigkeiten.
Dabei sind Tasks abgegrenzte Arbeitsschritte innerhalb eines Workflows. Sie werden über sogenannte Operatoren umgesetzt, welche wiederum die zu orchestrierenden Arbeiten auslösen, wie SQL-Statements oder Shell-Kommandos. Die Abhängigkeiten zwischen Tasks werden explizit im Code definiert und bestimmen, unter welchen Bedingungen ein Task ausgeführt wird. Dadurch entsteht ein klar strukturierter und eindeutig nachvollziehbarer Ablauf.
Insbesondere für umfangreichere Workflows bietet Airflow zusätzlich Task Groups, mit denen sich zusammengehörige Tasks logisch bündeln lassen. Abhängigkeiten können nicht nur zwischen einzelnen Tasks, sondern auch zwischen ganzen Gruppen definiert werden. Task Groups lassen sich dabei flexibel im Code erzeugen, was insbesondere bei datengetriebenen oder wiederkehrenden Ladeprozessen eine skalierbare Modellierung ermöglicht.
Codebeispiel: Ein einfacher DAG
Nachfolgend ist ein einfaches Codebeispiel für einen DAG dargestellt.
from datetime import datetime
from airflow import DAG
from airflow.providers.standard.operators.python import PythonOperator
from airflow.providers.standard.operators.bash import BashOperator
def check_prerequisites():
print("Checking prerequisites for data load")
def load_data():
print("Loading data into target system")
with DAG(
dag_id="daily_data_load",
start_date=datetime(2026, 1, 1),
schedule="0 0 * * *",
catchup=False,
) as dag:
check = PythonOperator(
task_id="check_prerequisites",
python_callable=check_prerequisites,
)
load = PythonOperator(
task_id="load_data",
python_callable=load_data,
)
finalize = BashOperator(
task_id="finalize_run",
bash_command="echo Data load completed",
)
check >> load >> finalizeDieses Beispiel zeigt einen einfachen, täglichen Ladeprozess mit eindeutig definierten Verarbeitungsschritten und Abhängigkeiten. Die Reihenfolge der Tasks wird am Ende des Codes über die Bitshift-Operatoren (») festgelegt. Jeder Task übernimmt eine abgegrenzte Aufgabe, während der DAG den zeitlichen Ablauf und die Reihenfolge der Ausführung steuert. Der Workflow startet ab dem 1. Januar 2026 und wird anschließend täglich um 00:00 Uhr ausgeführt.
Darstellung und Monitoring in der Airflow-GUI
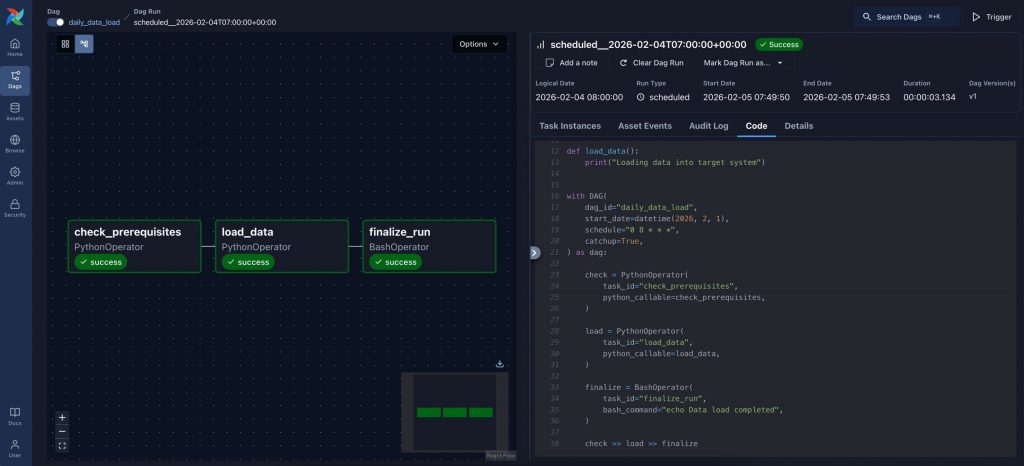
Nachdem der DAG definiert und im Code beschrieben ist, stellt Airflow den Workflow automatisch in der grafischen Benutzeroberfläche dar. Die Airflow-GUI bietet dabei eine visuelle Übersicht über alle Tasks, deren Abhängigkeiten sowie den aktuellen Ausführungsstatus.
Die Abbildung 2 zeigt den zuvor definierten Workflow. Jeder Task erscheint als eigener Knoten, die Verbindungen verdeutlichen die Abhängigkeiten und die festgelegte Ausführungsreihenfolge. Statusinformationen, Laufzeiten, Logs und Code sind einsehbar.
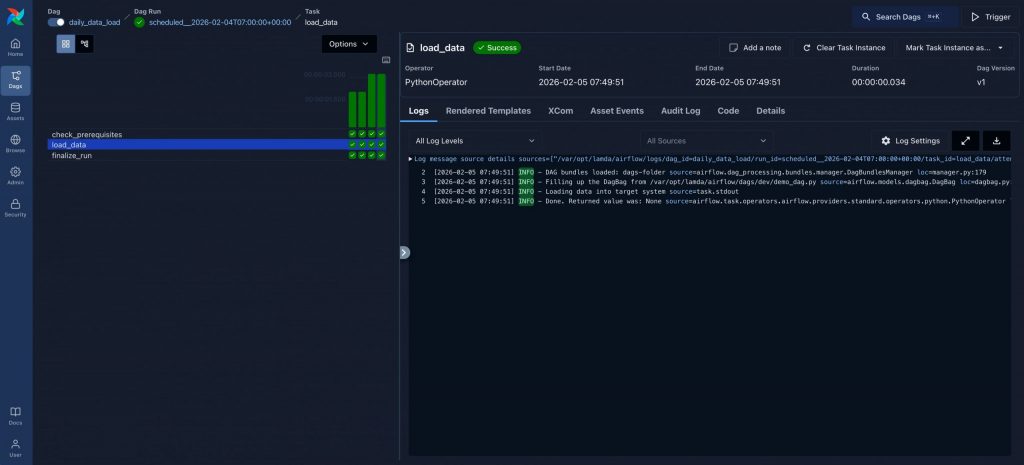
Gleichzeitig lassen sich über die Airflow-GUI auch mehrere Runs sowie deren Logs überwachen (Abbildung 3).
Airflow besteht aus mehreren Komponenten, die gemeinsam einen stabilen Orchestrierungsaufbau bilden:
| Komponente | Aufgabe |
|---|---|
| Scheduler | Plant und triggert Tasks entsprechend der DAG-Definitionen. |
| Executor | Führt die Tasks aus – entweder lokal oder parallel über mehrere Ausführungseinheiten. |
| Triggerer | Überwacht Ereignisse und Abhängigkeiten, ohne laufende Tasks unnötig zu blockieren. |
| API Server | Stellt sowohl die REST-API als auch die Web-GUI bereit. |
| DAG-Processor | Liest, parst und verarbeitet DAG-Dateien getrennt vom Scheduler. |
In der eingesetzten Installation wird der LocalExecutor verwendet, wodurch Tasks parallel über Python-Subprozesse ausgeführt werden. Die Airflow-GUI wird über den integrierten API-Server bereitgestellt, sodass ein separater Webserver nicht erforderlich ist. DAGs und Operatoren liegen versioniert in Git, Logs werden lokal gespeichert. Dadurch bleiben Deployments reproduzierbar und Abläufe transparent.
Für eine vertiefende Betrachtung von Workflow-Management und Architektur wird auf Workflow-Management mit Apache Airflow verwiesen.
Umsetzung der Migration zu Apache Airflow
Der Wechsel zu Airflow ist nicht nur ein technischer Umstieg, sondern eine grundlegende Neuausrichtung. Ziel ist es, die aktuell eingesetzte Logik in eine strukturierte, programmierbare Form zu überführen. Die Migration von der alten Orchestrierung zu Airflow erfordert eine Überführung der Logik, ohne dass bestehende Komplexität in das neue System übertragen wird.
Analyse der JSON-Strukturen
Zunächst werden die vorhandenen JSON-Konfiguration sowie die relevanten Steuerinformationen analysiert und extrahiert. Dazu zählen unter anderem Ladegruppen, Parameter, Plan- und Jobabhängigkeiten sowie Triggerlogiken. Viele dieser Konzepte lassen sich in Airflow mit wenigen Zeilen Code deutlich kompakter und optimierter abbilden.
Python-2-Tools zu wiederverwendbaren Operatoren
Die eigentliche Verarbeitungslogik ist bereits im alten System in Form von Python-2-Tools vorhanden. Diese werden nach Erfassung des Funktionsumfangs als neue Airflow-Operatoren entwickelt. Die Operatoren kapseln die Tools sauber, Parameter und Abhängigkeiten werden direkt im Code definiert, und die gesamte Ausführung ist zentral nachvollziehbar. Dadurch entsteht eine deutlich wartbarere und transparentere Steuerung als zuvor.
Parallelbetrieb und kontrollierter Übergang
Um Risiken zu vermeiden, laufen altes und neues System für einen definierten Zeitraum parallel. Erst nach vollständiger Übereinstimmung der Ergebnisse wird die alte On-Prem-Orchestrierung abgeschaltet.
Ergebnisse und Vorteile in der Praxis
Der Umstieg auf Airflow bringt unmittelbar spürbare Verbesserungen. Transparenz, Fehleranalyse und Wiederholbarkeit sind integraler Bestandteil der Plattform. Laufzeiten und Logs sind zentral einsehbar, einzelne Tasks lassen sich gezielt neu starten, und Änderungen erfolgen versioniert im Code statt verteilt über zahlreiche Konfigurationsdateien.
Somit lassen sich neue Prozesse schneller auf Basis von bestehender Operatoren entwickeln. Gleichzeitig sorgt die integrierte Fehlerbehandlung für stabile Abläufe, und das System kann mit steigenden Anforderungen problemlos skaliert werden.
Mehr als ein technisches Upgrade
Die Einführung von Apache Airflow bedeutet mehr als eine reine Ablösung bestehender Technik. Sie steht für den Schritt hin zu einer etablierten, weit verbreiteten Open-Source-Orchestrierungsplattform.
Workflows werden nicht mehr implizit über Konfigurationsdateien gesteuert, sondern explizit als Python-Code modelliert. Dadurch entstehen klare Strukturen, versionierbare Änderungen und nachvollziehbare Abhängigkeiten. Code-Reviews, Tests und kontinuierliche Weiterentwicklung sind fester Bestandteil des Entwicklungsprozesses.
Damit wird die Orchestrierung insgesamt klarer, wartbarer und leichter erweiterbar. Neue Anforderungen können systematisch integriert werden, ohne dass existierende Prozesse an Übersicht verlieren. Darüber hinaus steht mit Apache Airflow eine aktiv weiterentwickelte Plattform zur Verfügung, die technologisch anschlussfähig bleibt und langfristige Stabilität bietet.
Fazit zur Migration zu Apache Airflow
Der laufende Übergang von der eigenentwickelten On-Prem-Orchestrierung zu Apache Airflow steht für die Weiterentwicklung einer gewachsenen Steuerungsstruktur hin zu einer modernen, standardisierten Workflow-Plattform.
Während das bestehende System weiterhin stabil arbeitet, wird mit Apache Airflow die Orchestrierung neu strukturiert. Die Abhängigkeiten sind klar definiert, Workflows sind als Code beschrieben und Wartung sowie Erweiterung werden vereinfacht. Gleichzeitig basiert die neue Steuerung auf einer im Data-Engineering-Umfeld etablierten Plattform. Apache Airflow orchestriert unterschiedlichste Technologien und lässt sich durch vorhandene sowie eigene Operatoren flexibel erweitern.
Dadurch entsteht eine tragfähige Grundlage für zukünftige Anforderungen im DWH- und ETL-Umfeld, die strukturiert, nachvollziehbar und langfristig zukunftsfähig ist.











