
Die Kunst der Konsolidierung: Harmonisierung eines Multi-Mandanten-DWH in einer On-Premises-Welt

Während sich Cloudlösungen zunehmend als Standard etablieren, setzen dennoch viele Unternehmen weiterhin auf ihre bestehenden On-Premises-Systeme – getrieben durch regulatorische Anforderungen, spezifische Sicherheitsvorgaben oder historisch gewachsene Infrastrukturen. Die eigentliche Herausforderung beginnt jedoch, wenn diese traditionellen Systeme die Basis für zukunftsweisende Technologien wie KI oder Advanced Analytics bilden sollen: Hierfür ist ein harmonisierter, konsistenter Datenstand die absolute Grundvoraussetzung.
In diesem Beitrag beleuchten wir ein architektonisch anspruchsvolles Szenario aus der Retail-Branche. Wir zeigen konkret, wie wir ein komplexes On-Prem Multi-Mandanten-DWH transformiert haben, nachdem die Quellsysteme bereits zu einem globalen Einheitssystem konsolidiert worden waren. Dabei blicken wir auf das spannende Zusammenspiel zwischen einer strukturellen Vereinfachung an der Quelle und der notwendigen logischen Präzision im Data Warehouse, um den Brückenschlag zwischen historischer Tiefe und moderner Ein-System-Logik zu meistern.
Das Datenökosystem: Vom lokalen Silo zur globalen Vision
Um die Komplexität dieses Projekts zu verstehen, müssen wir uns die Ausgangslage vor Augen führen. Wir befinden uns in einem klassischen, international agierenden Retail-Umfeld. In der ursprünglichen Struktur pflegte jedes Land seine eigenen Daten mit einer jeweils eigenen Codierungslogik in einem isolierten, länderspezifischen System. Für die IT bedeutet dies folglich: Jedes neue Land brachte eine weitere isolierte ERP-Instanz mit sich. Es gab eigene Artikelstämme und individuelle Prozesse zur Verbuchung der Verkäufe.
Diese Zersplitterung war das Hindernis für unser übergeordnetes Ziel: die Schaffung einer unternehmensweiten Analysefähigkeit. Um Synergien zu nutzen und Prozesse global zu steuern, wollte das Unternehmen weg von den lokalen Insellösungen. Die Vision war ein einheitliches, globales System, in dem alle Länderdaten zentral gepflegt werden. Ein Artikel sollte überall die gleiche Definition haben, und ein Prozess sollte in Wien genauso ablaufen wie in Berlin.
Die Architektur der Datenstrecke
In unserer zugrundeliegenden Datenarchitektur ist der Weg eines Datensatzes klar definiert: Die Daten werden aus verschiedenen Datenquellen durch ETL-Jobs ingestiert und als erste Zwischenschicht in dedizierten Ländertabellen in einem Operational Data Store (ODS) in relationalem Format transformiert und gestaged. Unsere Philosophie lautet hier: So quellennah wie möglich speichern. Nur so bleibt die volle Rückverfolgbarkeit (Data Lineage) erhalten.
Während die Daten im ODS nur für einen flüchtigen Zeitraum für operative Zwecke aufbewahrt werden, findet die eigentliche „Veredelung“ erst im weiteren Verlauf beim Transfer in das Data Warehouse (DWH)-System statt. Die ODS-Daten werden mit technischen Validierungen, Datenanreicherungen und Datentyp-Bereinigungen in das DWH-System übertragen. Hier werden die Daten in ländergetrennten Schemata über mehr als zehn Jahre archiviert. Diese historisierten Daten bilden die Grundlage für unsere BI-Tools. Sie ermöglichen ein fundiertes, nachhaltiges Berichtswesen über lange Zeitreihen hinweg.
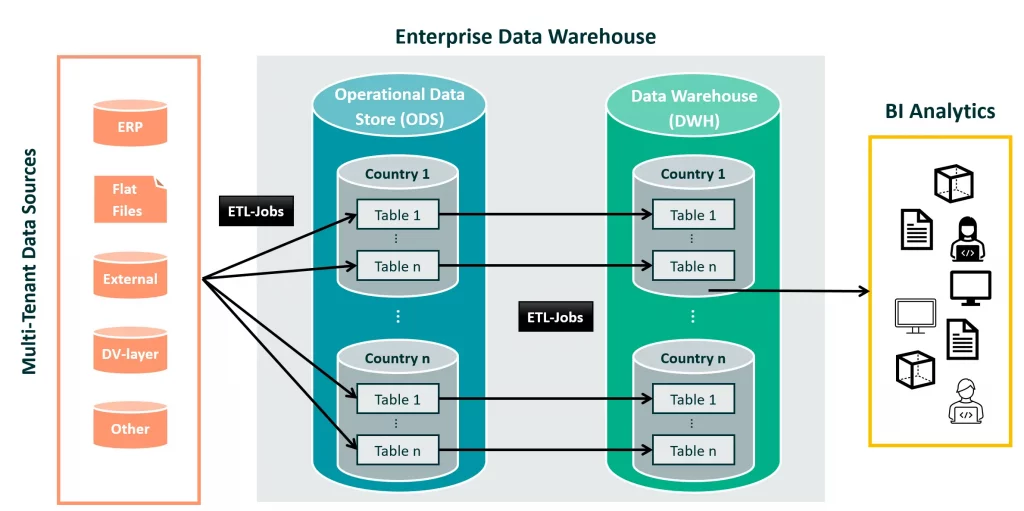
Zielbild-Strategie: Die globale Vision in bestehender Datenarchitektur verankern
Während die oben beschriebene Architektur den stabilen Rahmen für den Datenfluss bildet, prallt diese Struktur nun auf die veränderte Realität der neuen System-Vision. Die Einführung eines globalen Einheitssystems, das alle Länderprozesse harmonisiert, war zwar ein bedeutender Meilenstein für die IT-Landschaft, stellte uns aber in der DWH-Landschaft vor zwei Kernfragen:
- Wie definieren wir, zu welchem Land jeder Datensatz gehört? Bisher war die Ländererkennung im DWH implizit gelöst. Da die Daten aus physikalisch getrennten Quellsystemen flossen, wussten wir durch die Identifikation der Quelle exakt, welcher Datensatz zu welchem Land gehörte. Das passte perfekt zu unserer Multi-Mandanten DWH-Architektur. Mit der Einführung des harmonisierten Einheitssystems verschwand diese Grenze. Plötzlich landeten alle Daten „in einem Topf“, und wir mussten neue Wege finden, um die Herkunft für unsere Berichte präzise zu steuern.
- Wie vereinen wir die harmonisierte Logik und bestehende Strukturen? Ein kritischer Aspekt unserer ländergetrennten Datenarchitektur war die historisch gewachsene Isolation der Codierungen. Da die Quellsysteme über Jahrzehnte länderspezifisch getrennt betrieben wurden, herrschte eine tiefe semantische Inkonsistenz vor. Beispielsweise entsprach die Artikelnummer 1234 in Hamburg oft einem völlig anderen Artikel mit derselben ID in Zagreb. Durch die Harmonisierung war es unser erklärtes Ziel, diese Codierungen so zu konsolidieren, dass jede ID eine eindeutige, unternehmensweite Bedeutung aufweist. Nur so konnte sichergestellt werden, dass Analysen über verschiedene Standorte hinweg nicht „Äpfel mit Birnen“ vergleichen.
Somit wurde unsere Datenarchitektur mit der strikten Trennung in länderspezifische Schemata im DWH und der jahrelangen Historisierung durch das neue Quellsystem auf eine positive Weise herausgefordert. Wir mussten eine Lösung entwickeln, die sowohl die neue „Ein-System-Welt“ als auch die „länderspezifische Historie“ nahtlos vereint.
Strategische Planung: Warum kein „Big Bang“?
Angesichts dieser Herausforderungen stellte sich die Frage nach der Umsetzungsstrategie. Ein vollständiger „Big Bang“ mit vollständiger physischer Migration und Umschlüsselung aller historischen Bestände war angesichts begrenzter On-Prem-Serverkapazitäten nicht praktikabel. Außerdem ist das tägliche Datenvolumen im Terabytes-Bereich zu groß. Ein solcher Schritt hätte die Systeme für Tage lahmgelegt. Folglich wäre das Risiko für Datenverluste und Inkonsistenzen zu hoch gewesen.
Aus diesem Grund entschieden wir uns für eine hybride Architektur, die Sicherheit und Fortschritt vereinte: Während die Quelle nun einheitlich agierte, behielten wir im DWH-Storage die mandantenspezifische Trennung bei. Die Lösung für die Analyseebene war eine Abstraktionsschicht mit Union-Views. Diese virtuellen Schichten führen die Daten der verschiedenen Länder logisch zusammen und präsentieren den BI-Anwendungen ein harmonisiertes Gesamtbild mit dem Länderkennzeichen als zusätzlichen fachlichen Schlüssel. So konnten wir die Performance stabil halten, ohne die bewährte historische Datenbasis physisch umschreiben zu müssen.
1. Kernfrage: Wie gelingt die Landeszuordnung?
Da das Quellsystem keine physikalische Trennung mehr vorgab, war die Identifikation geeigneter Attribute zur Landeserkennung unsere erste große Hürde. Ein solches Merkmal muss zwei entscheidende Eigenschaften haben: Einerseits muss es über alle Länder hinweg konsistent verwendet werden. Andererseits muss es innerhalb der gesamten Organisation eine einheitliche Bedeutung besitzen.
Die fachliche Perspektive: Kontext ist alles
Hinter den Kulissen der SQL-Abfragen spielt die fachliche Perspektive eine entscheidende Rolle. Wir lernten schnell, dass „Land“ schließlich nicht gleich „Land“ ist. Besonders bei logistischen Daten ist die Sichtweise entscheidend, ob man die Landeszuordnung aus Sicht der Verkaufsorganisation (VKORG) oder der Einkaufsorganisation (EKORG) vornimmt. Speziell bei internationalen Inter-Company-Prozessen weichen die Einkaufs- und Verkaufsländer voneinander ab. Die Daten eines Verteilzentrums in einem benachbarten Land, das eine Filiale in Deutschland beliefert. Dementsprechend flaggen wir die Daten je nach Berichtsanforderung unterschiedlich.
Nach einer gründlichen Business-Analyse und vielen Interviews mit den Fachbereichen konnten wir mit Berücksichtigung der Anforderungen im Berichtwesen folgende Attribute für diesen Zweck identifizieren:
- Einkaufs- und Verkaufsorganisationen für logistische sowie Betriebs- oder Distributionsdaten.
- Betriebs‑, Filial- oder Verteilzentrum-IDs für Immobilien- oder Sortimentsdaten.
- Der Buchungs- oder Kostenrechnungskreis für Finanz- und Rechnungsdaten.
- Sprachschlüssel für Stammdaten mit Text oder Produktbeschreibungen.
Technische Umsetzung und ISO-Standards
Um die Ländererkennung datengetrieben und zukunftssicher umzusetzen, definierten wir zentrale Referenztabellen. Für eine konsistente Abbildung nutzten wir konsequent das zweistellige ISO-3166-Alpha-2-Format. Dementsprechend wird in unseren ETL-Prozessen das Länderkennzeichen für jede eingehende ID automatisch ermittelt. Dafür haben wir zentrale Lookups oder User-Defined-Functions (UDF) eingesetzt.
Detailbetrachtung: Sprachschlüssel als Beispiel
Ein besonders spannendes Merkmal für die Landeserkennung der Artikelbeschreibungen in einem Retail-System ist der Sprachschlüssel. Allerdings zeigten sich genau hier zwei technische Knackpunkte, die eine besonders raffinierte Ausgestaltung der ETL-Logik erforderten.
1. Die Vorgehensweise bei Default-Sprachen: In vielen Systemen wird eine Sprache (oft Englisch oder die Konzernsprache) als „Default“ definiert. Das bedeutet: Liegt keine spezifische Beschreibung in der Landessprache vor, wird auf den Default-Text zurückgegriffen. Technisch bedeutet das: Wir müssen diese Default-Datensätze in alle relevanten Ländertabellen replizieren, sofern zu dem Primärschlüssel kein Datensatz in Landessprache vorhanden ist. Um sicherzustellen, dass nicht beide Einträge im DWH landen, implementierten wir eine Priorisierungslogik mittels Windowing-Funktion, die in dem letzten Schritt vor dem Laden der Daten in DWH prüft, ob bereits ein Datensatz in der Landessprache existiert. Falls ja, wird der Default-Eintrag verworfen.

2. Sprachüberschneidungen: Die zweite Herausforderung ist geografisch-sprachlicher Natur: Länder wie Deutschland und Österreich oder Serbien und Bosnien teilen sich oft denselben Sprachschlüssel. Hier reicht ein einfacher 1‑zu-1-Lookup nicht aus. In solchen Fällen haben wir mit einem Left-Join die Datensätze in die relevanten Ländertabellen repliziert. Das heißt, dass die Daten gegebenenfalls vervielfacht bzw. konkret im Falle von Deutschland und Österreich verdoppelt werden.

2. Kernfrage: Brückenschlag zur Historie
Die komplexeste fachliche Herausforderung in diesem Projekt war der Umgang mit der über zehnjährigen Historie. Da das neue Quellsystem eine völlig neue, harmonisierte Codierungslogik einführte, mussten wir eine Brücke zwischen den alten länderspezifischen IDs und den neuen globalen Schlüsseln schlagen.
Herausforderung 1: Die Gefahr der ID-Kollision beim Mapping
Bevor wir uns den technischen Details widmeten, mussten wir ein existenzielles Risiko adressieren: ID-Überschneidungen zwischen altem und neuem System. Unser Architekturansatz sieht vor, dass neue IDs aus der Quelle zunächst gegen Mapping-Tabellen geprüft werden. Findet sich eine Übersetzung, erfolgt die Umschlüsselung auf die alte ID. Findet sich keine, wird sie als neuer Datensatz verarbeitet. So gewährleisten wir die Analyse der historischen Daten, während gleichzeitig neue IDs aus dem harmonisierten System 1:1 im DWH verarbeitet werden können.
Die Gefahr dabei: Wenn eine neue ID zufällig identisch mit einer bereits existierenden alten ID ist, würden historische Daten fälschlicherweise überschrieben. Nehmen wir an, der neue Lieferant Bienlein Logistik erhält im neuen System die ID 65934. Da Bienlein Logistik neu ist, gibt es kein Mapping zu der ID. Der ETL-Prozess würde deshalb diese ID 1:1 ins DWH schreiben. Doch im DWH existiert bereits seit Jahren der Lieferant Pingu Gutmann mit genau dieser alten ID 65934. Ohne eine strikte Trennung der Nummernkreise würde das System die historischen Daten von Pingu Gutmann mit den Informationen der Bienlein Logistik überschreiben. Dieser „Clash“ musste durch eine sorgfältige Definition der neuen Nummernkreise für kritische Attribute wie Lieferanten- oder Artikelnummern im Vorfeld zwingend ausgeschlossen werden.
Herausforderung 2: Datentyp-Konflikte
Ein technisches Highlight war die Harmonisierung der Versandstellen. Im On-Prem DWH war das Attribut Versandstelle als SMALLINT (bis 32.767) definiert. Die Fachabteilung wünschte sich jedoch neue IDs, die ein Landes- und Regionalmerkmal enthalten sollten, um die Herkunft auf den ersten Blick für die Fachanwender erkennbar zu machen.
Da wir den Datentyp nicht global ändern konnten, nutzten wir einen technischen Kniff: Eine Basis-24-Codierung. Die neue ID setzt sich aus einem Buchstaben für das Land, einer 2‑stelligen Regionalnummer in Basis 24 und einer lokalen laufenden Nummer zusammen. Mathematisch ermöglichte dies dem Fachbereich die Definition von bis zu 575 (24 * 24 – 1) unterschiedlichen Versandstellen-IDs – ein komfortabler Puffer nach oben. Technisch wandelten wir die Basis-24-Komponente in einen Dezimalwert um und hängten die laufende Nummer an, um die IDs mathematisch in die bestehende SMALLINT-Logik zurückzuführen und gleichzeitig sicherzustellen, dass die IDs eindeutig bleiben.
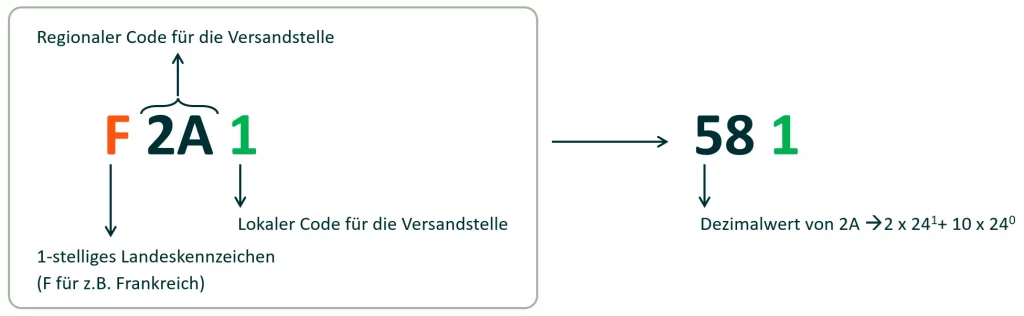
Herausforderung 3: Dynamische Nummernkreise
Für Attribute wie Belegnummern (Rechnungen, Bestellungen) bezogen wir uns primär auf das laufende Geschäftsjahr. Ab der Migration wurden beispielsweise Rechnungsnummern 10-stellig mit einer führenden „8“ definiert. Diese Umschlüsselung ist weitgehend unabhängig von der tiefen Historie umsetzbar, da ab dem neuen Geschäftsjahr ohnehin der neue harmonisierte Nummernkreis greift. Dennoch war hier unternehmensübergreifendes Fachwissen gefragt, um sicherzustellen, dass Nummernkreise für unterschiedliche Belegarten konsistent über alle Länder hinweg definiert wurden.
Zusammenfassung: Technische Meilensteine der Harmonisierung
Blicken wir auf das Projekt zurück, lassen sich die zentralen technischen Erfolge zusammenfassend in drei Säulen unterteilen:
- Virtuelle Konsolidierung statt physischer Migration: Die Entscheidung gegen den „Big Bang“ und für die Union-View-Architektur war der Schlüssel zum Erfolg. Sie ermöglichte es uns, die neue, harmonisierte Quellwelt sofort nutzbar zu machen, während die Petabytes an historischen Daten sicher und performant in ihren ursprünglichen Schemata verblieben.
- Intelligente Identifikation im ETL-Layer: Durch die Nutzung von ISO-Standards und kontextabhängigen Attributen (wie VKORG/EKORG oder Sprachschlüsseln) haben wir die verloren gegangene länderspezifische Identität der Daten im harmonisierten Datenstrom erfolgreich rekonstruiert.
- Mathematische Brückenschläge: Lösungen wie die Basis-24-Codierung zeigen, dass man technische Limitationen (wie starre Datentypen in On-Prem-Systemen) durch mathematische Logik überwinden kann, ohne die Datenintegrität zu opfern.
Fazit: Datenengineering als Brücke zwischen Business und Technologie
Die Harmonisierung eines Multi-Mandanten-DWH in einem internationalen Retail-Umfeld ist weit mehr als eine reine Datenbankoperation. Sie erfordert vielmehr ein tiefes Verständnis für die Geschäftshistorie, die logistischen Abläufe und eine klare Vision für die Zukunft.
Wir haben gelernt, dass eine erfolgreiche Harmonisierung an der Quelle (das „Ein-System-Ziel“) zwangsläufig neue Aufgaben im DWH erzeugt. Die Kunst des Data Engineering besteht hier darin, diese Anforderungen durch intelligente Mapping-Logiken und virtuelle Layer abzufangen.
Heute ist unser System weit mehr als nur ein digitales Archiv. Es ist ein konsistentes, unternehmensweites Fundament. Die Brücke zwischen der „alten“ länderspezifischen Welt und der „neuen“ globalen Logik ist geschlagen. Infolgedessen bietet sie die perfekte Startrampe für Advanced Analytics und KI-Projekte, die auf eine saubere, historisierte Datenbasis angewiesen sind. On-Prem ist in diesem Kontext kein Hindernis, sondern – mit den richtigen Kniffen – eine hochstabile und leistungsfähige Plattform für die Zukunft.
















