
Structured Testing in Data Warehousing: From Chaos to Control
Introduction: Why Testing a DWH is necessary – and difficult
In today’s data-driven organizations, a robust Data Warehouse Testing Strategy is the foundation of reliable analytics and business decisions. Yet many companies underestimate the complexity of testing this core system, often leading to «data chaos». When a data warehouse delivers incorrect or incomplete results, the consequences are severe: loss of trust, financial losses, and costly repair loops.
Imagine the familiar “worst-case scenario”:
A controller notices that key figures in the monthly report look suspiciously low. The BI team insists the report is fine; data engineering confirms the ETL jobs ran successfully. Days later, it turns out that an entire product area was missing due to an untested filter condition. Meanwhile, the business switches to Excel, confidence in the data platform collapses, and the CFO questions the entire investment.

Why Testing Is Essential
Testing is not just a formality — it’s the foundation of data quality and trust. Structured testing ensures:
- Improved quality: errors are detected early and systematically, not by chance in production.
- Stable operations: fewer production incidents and early detection of data drift.
- Transparency and compliance: every transformation is verifiable, auditable, and reproducible.
- Trust in data: reliable reports enable confident decision-making across the business.
Without a solid testing framework, organizations risk operating in a “test chaos” environment — inconsistent test data, unclear responsibilities, and growing skepticism from business users.
Why Data Warehouse Testing Is Different
Testing in a data warehouse is fundamentally different from testing classic applications. There’s no user interface, no buttons to click, and often no simple “pass or fail” outcome. The focus lies on data flows, data quality, and transformation logic — aspects that are invisible without analytical checks.
A few key challenges make DWH testing unique:
- Silent failures: data can disappear or be duplicated without obvious symptoms.
- Complex expectations: defining correct values requires deep business knowledge and analytical comparison across tables and aggregates.
- Data drift: source systems evolve, new columns appear, formats change — tests that passed for months can suddenly fail.
- Test data realism: representative and up-to-date data is hard to create, especially when anonymization and business logic need to be preserved.
- Error propagation: an error in one ETL process may only surface in a dashboard days later.
In short, testing a DWH means testing the invisible — ensuring that every transformation, every join, and every aggregation behaves as intended across vast volumes of data. Furthermore, testing in data warehousing is not a one-time task; it’s a continuous quality discipline. When done right, it:
- Strengthens collaboration between IT and business,
- Prevents expensive rework and data-related outages, and
- Builds lasting confidence in analytics and reporting systems.
In this blog, you will learn where to start when designing a Test strategy for a DWH, what test levels could make sense to you and your project and how you can use AI created test data to empower your transformation testing.
Doing the Right Thing: Requirements on the Test Bench
In agile data warehouse development, testing doesn’t start when the first ETL job is deployed — it starts long before a single line of code is written. The quality of your tests can never exceed the quality of your requirements. That’s why structured testing must begin with the static testing of requirements.
Why Static Testing Matters
Most data quality problems are not caused by broken code, but by unclear, incomplete, or contradictory requirements. A vague statement such as
“The system must react quickly”
or
“The report should always be up to date”
may sound reasonable, but it is unmeasurable and untestable.
Static testing helps identify such ambiguities early, before they turn into costly rework later in the project. The goal is simple: find errors as early as possible, when they are still cheap to fix. This will lead to:
- Reduced defects during development and production.
- Improved collaboration between business and IT through clarified expectations.
- Faster test preparation, since test cases can be derived directly from clear acceptance criteria.
- Higher auditability and compliance for regulated environments.
Most importantly, it ensures that you are doing the right thing — not just building the system right, but building the right system.
Static vs. Dynamic Testing
Unlike dynamic testing — which verifies actual system behavior by executing code — static testing means reviewing requirements, designs, and mappings without running anything. It’s about checking whether the planned solution is logically sound, consistent, and testable.
Typical methods include:

- Coffee review: quick, informal peer checks to catch obvious issues.
- Walkthrough: the author explains the requirement to the team to gather feedback and clarify open points.
- Sign-off review: a structured review with defined acceptance criteria and traceability.
- Formal inspection or external audit: required for system-critical or regulatory data processes.
The earlier you perform these checks, the fewer surprises appear downstream in ETL logic, reports, or acceptance testing. Whereas Sign-Offs and External audits are suitable for large-scale waterfall projects, i.e., long-running projects with a large specification up-front, smaller work items in agile projects allow for walkthroughs or coffee reviews. Especially in agile environments, every backlog item should meet a Definition of Ready before it can enter development. The DoR ensures that requirements are:
- Clear and unambiguous – everyone understands the same thing.
- Quantifiable and measurable – the outcome can be objectively verified.
- Complete and consistent – no missing dependencies or contradictions.
- Testable – expected results and acceptance criteria are explicitly defined.
Only when a requirement fulfills the DoR is it ready for implementation — and later for meaningful automated or manual testing. In the following, you will learn how to design such a test process for a data warehouse.
3. Towards a Solid Test Strategy for a Data Warehouse
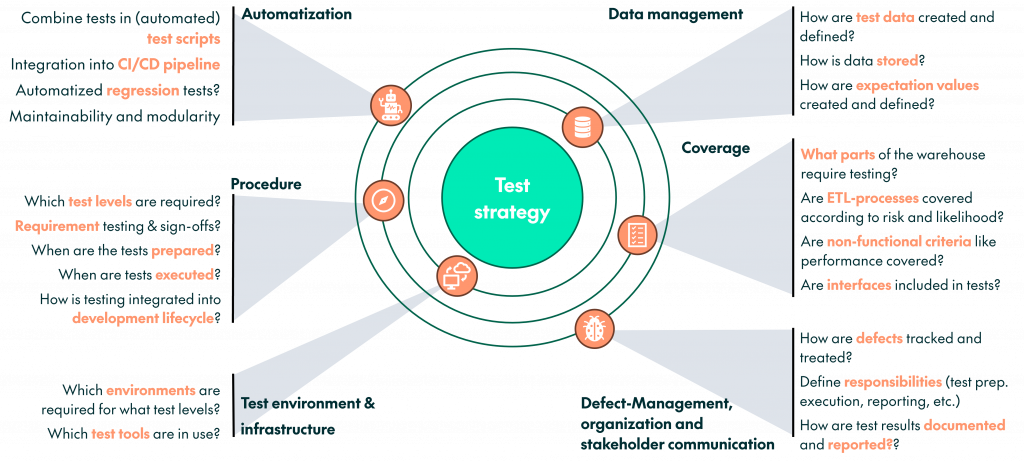
A good data-warehouse test strategy is the backbone of reliable analytics. Without a structured approach, even the best ETL logic can fail under real-world complexity. A strategy defines who tests what, when, and how — and ensures that every data flow is verified consistently across layers.
A robust strategy typically includes:
- Clear Test Objectives – Define what success means: data accuracy, stability, performance, or compliance.
- Defined Test Levels – From unit to integration, system, and user acceptance testing (details in the next chapter).
- Ownership and Roles – Establish who is responsible for test design, execution, and approval across business and IT.
- Test Data Management – Prepare realistic, anonymized, and repeatable test data sets reflecting production conditions.
- Automation and Regression Testing – Integrate repeatable tests into CI/CD pipelines to ensure continuous quality.
- Traceability and Documentation – Link tests to requirements and expected outcomes for auditability and learning.
- Continuous Improvement – Regularly review test coverage and adapt to data drift, new sources, or business changes.
When setting up a testing strategy for your project, you can use the following checklist to see whether all relevant questions have been clarified.
4. Defining the Required Test Levels in a Data Warehouse
A structured test strategy comes to life through defined test levels. Each level targets a specific scope — from verifying individual transformations to ensuring that the entire data flow, from source system to report, works as intended. Together, these levels form a comprehensive test process that ensures data quality, stability, and business trust.
Overview of a Typical DWH Test Process

A simplified test process in data warehousing often includes the following stages:
- Requirement Testing – Validate that requirements are clear, testable, and meet the Definition of Ready. See corresponding section above.
- Test planning – Define what will be tested, by whom and when.
- Test preperation – The test execution is prepared by creating test cases and data for integration, system, and user-acceptance tests.
- Development – Parallel to test preperation, the development of the ETL pipelines takes place.
- Unit Testing – Verify correctness of individual ETL processes or transformations.
- Integration Testing – Test the interaction between multiple pipelines and layers (e.g., staging to core).
- System Testing – Validate the end-to-end data flow and non-functional requirements like performance.
- User Acceptance Testing (UAT) – Confirm that the data warehouse delivers the expected business value.
- Regression Testing – Continuously revalidate stability and correctness after changes or new releases.
Note that the different test levels may overlap or run in parallel depending on the project setup — agile environments, for instance, often combine integration and system testing into iterative delivery cycles. Further, not all test levels are executed with the same intensity in every project. However, clarifying which ones are required, and how they interlink, is essential for sustainable DWH quality.
5. From Theory to Practice: Navigating the Test Levels
Now that we’ve laid the groundwork with a solid strategy and static requirements testing, it’s time to get our hands dirty. In a data warehouse, testing isn’t a monolithic «check» at the end of the project—it’s a multi-layered process designed to catch everything from a single broken calculation to a full-scale system collapse.
Think of these test levels as filters: each one is designed to catch a specific «size» of error before it can pollute your downstream reports.
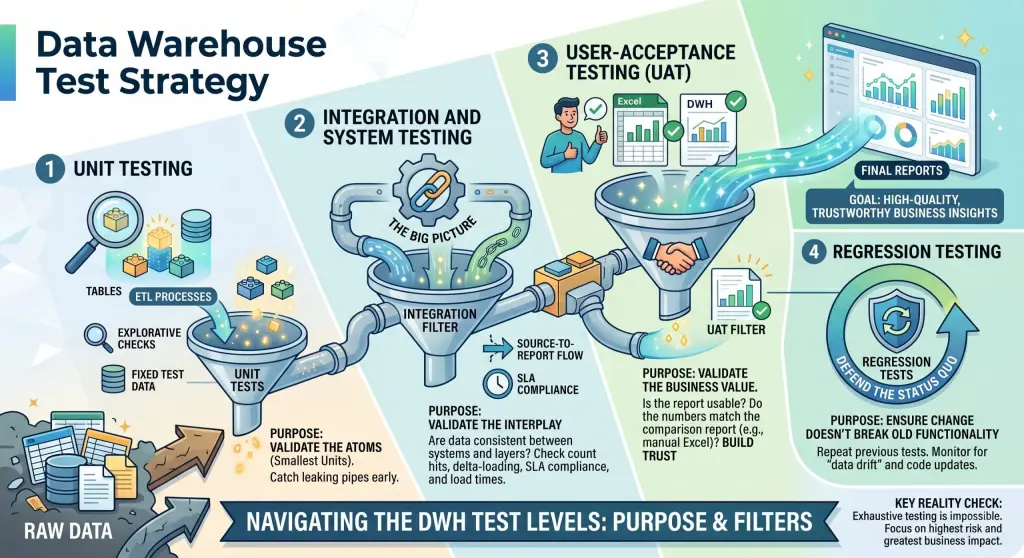
Unit Testing: The Smallest Building Blocks
Unit testing focuses on the atoms of your DWH: Tables (the smallest data unit) and ETL-processes (the smallest transformation unit). At this level, we aren’t worried about the whole system yet; we just want to know if this specific pipe is leaking.
There are two primary ways to approach this:
- Explorative Table Testing: Developers or testers use rule-based plausibility checks to hunt for null values, incorrect formats, or historization errors. It’s low effort but limited by the data currently available.
- Fixed Test Data Testing: This is the gold standard for automation. We define a specific set of test data where 1 row = 1 test case. We define exactly what we expect the target layer to look like, run the ETL, and compare the results. It’s higher effort to set up, but it’s reproducible and fits perfectly into a CI/CD pipeline.
Integration and System Testing: The Big Picture
Once the individual units are verified, we need to see how they play together. In the DWH world, these two levels often overlap because the «system» is essentially a long chain of integrations.
- Integration Testing: The focus here is the interplay of many pipelines using realistic data. We check if data remains consistent as it moves between different source systems and layers. Typical checks include count hits/misses in joins or verifying that delta-loading logic actually works.
- System Testing: This is the End-to-End validation. We look at the entire flow from the source system all the way to the final report. Beyond just «correct numbers,» we also test non-functional criteria like SLA compliance and load times. If the report is 100% accurate but takes 12 hours to load, the system has still failed the business.
User-Acceptance Testing (UAT): The Truth Serum
UAT is where we find out if we built the right system. This isn’t just about code; it’s about Business Rules and KPIs.
- Focus: Is the user’s need satisfied? Is the report usable?
- Validation: A common test condition is comparing a required Business KPI in the DWH to a «comparison report» (like the infamous manual Excel sheet the controller has been using for years). If the numbers match, you’ve earned their trust.
Regression Testing: Defending the Status Quo
In a DWH, change is the only constant. Whether it’s a code update or a change in the source system (data drift), you need to ensure that what worked yesterday still works today.
- Regression Tests repeat earlier tests (Unit, Integration, System) to detect if new changes broke old functionality.
- Data Monitoring: We regularly repeat data quality checks to find new NULLs or format changes introduced by source systems.
A Final Reality Check: Exhaustive testing is impossible. You will never catch every single edge case in a billion-row dataset. The secret to a successful DWH project isn’t testing everything—it’s focusing your testing efforts where the risk is highest and the business impact is greatest.
Summary
Data Warehouse (DWH) testing is more than a technical «bug check»—it is a continuous quality discipline designed to build business trust. Unlike standard software, DWH failures are often «silent,» making structured verification across several layers essential.
Key Pillars of the Strategy
- Static Testing First: Quality starts before coding. Reviewing requirements early (via Walkthroughs or «Definition of Ready») prevents the most expensive errors: building the wrong system.
- The Filter Principle: Testing is structured as a multi-layered filter process:
- Unit Testing: Validating «atoms» (tables/ETL) using explorative checks or fixed test data.
- Integration & System Testing: Ensuring the «big picture» works—validating data consistency across layers and meeting non-functional SLAs.
- User-Acceptance Testing (UAT): The «truth serum» where business KPIs are reconciled against legacy reports to earn stakeholder trust.
- Regression Testing: Protecting the status quo against code changes and «data drift» from source systems.
The Bottom Line: You cannot test every row in a billion-record set. Success lies in a risk-based strategy that prioritizes high-impact business logic to ensure the DWH remains a reliable foundation for decision-making.














