

The Journey of Data-Driven Transformation at a Leading Vehicle Manufacturer

In an era where data plays a crucial role within any company, Data Engineering has become one of the most important topics for industries looking to modernize and streamline their operations and decision making process. This is the story of our journey to a vehicle manufacturer in Europe, a company that sets the standard in vehicle excellence and where we were presented with a challenge.
Our challenge: To automate a number of manual tasks within their finance department, in order to increase operational efficiency, data quality, reduce human error and set a good foundation for the company to build from.
In this article we will go through:
- The Challenge: What is the problem?
- The Solution: What do we want to do?
- The Implementation: How do we want to do it?
- The Outcomes: What does success look like?
The Challenge
The finance department was spending extensive hours manually manipulating and validating data. Not only were its processes labor-intensive, but prone to errors as well, making financial reporting and analysis a time-consuming administrative challenge. Key challenges included:
- Manual Extraction: The process of extracting data was fully dependent on employee actions which could lead to delays and mistakes.
- Inconsistent Data Quality: With no automated process for data cleaning and transformation, the data quality was vulnerable to inconsistencies, leading to delays and affecting the accuracy of future financial reports.
- Limited Scalability: The manual processes were not scalable, constraining the department’s capability to handle the increasing volume of data and its complexity.
Being this project conducted by a company that is a prominent player in the vehicle distribution industry, it lead to several security considerations we needed to account for. One of them, which we would only find out later, being the highly confidential nature of the data and because of it, developing this solution remotely was simply not viable. In the end, we were asked to go to their headquarters in order to sync with their team and fully deploy the solution with the limitation of using their machines and tools.
The Solution
Our team’s solution was centered around automating the ETL (Extract, Transform, Load) processes using a data engineering pipeline, tailored specifically to meet the unique needs of the finance department. The solution included several key components:
- Automated Data Extraction: Extract the data in a streamlined and automated fashion, ensuring a timely and error-free procedure.
- Data Validation: Develop a standardized data validation protocol that generates error reports and forwards them to the respective department. The process primarily involved migrating the ‘hard-coded’ Excel formulas, which served as validations and required manual checks with each new Excel datasheet, to PySpark Data Manipulation methods.
- Data Correction and Restructure: Developing a suite of algorithms to clean and restructure the data into a consistent and standardized format. This step was of great importance to ensure data quality and reliability for downstream usage.
- Automated Data Loading: Automated load of the treated data into the database, shortening the time necessary for the data to be accessible.
- Task Scheduler: The nature of working with monthly financial reports provided us the opportunity to build a scheduler that would automatically retrieve the corresponding monthly datasheet on the X day of each month. We also took into account the potential delays in the availability of these datasheets. Therefore, we implemented safety measures to ensure that no files would be skipped and to prevent the data collection process from reaching a ‘deadlock’.
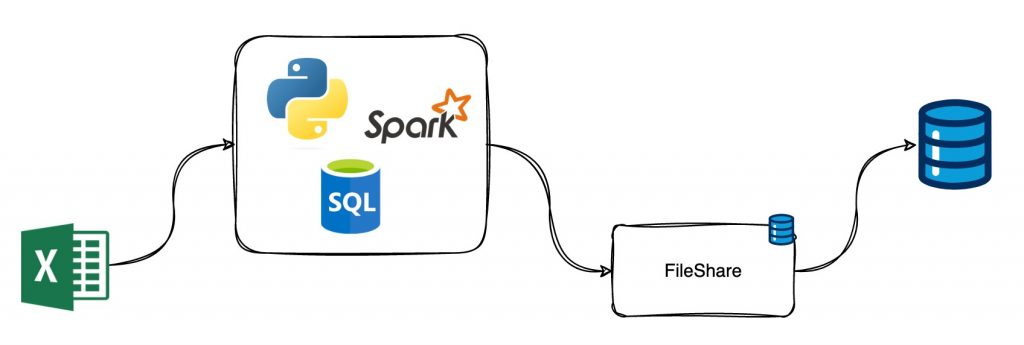
- The Deliverable: The project’s deliverable was to fetch data from a raw Excel file, load it into DataFrames using PySpark and SQL, and then check for errors, missing data, and typos. Once these issues were addressed, we uploaded the enhanced Excel file to their FileShare, allowing the financial team to review their data without quality concerns.
The Implementation Plan
The implementation phase was carefully planned to be delivered in stages to minimize any possible complications and ensure a smooth transition. Key steps included:
- Requirements Evaluation: Identification of the needs and constraints of the task at hand. Analyze the infrastructure that is currently in place to define a proper plan for integration.
- Solution Design: Design a custom ETL pipeline and choose the right tools to achieve the established goals effectively.
- Testing: Implement the solution in a controlled environment to assess its effectiveness and make necessary modifications.
- Support: Give clear instructions to the finance department staff on using the new system, and ensure availability to resolve any future issues.
The Actual Implementation
Preparation before arrival
Knowing that there were several infrastructure barriers that needed to be tackled once we arrived, since we would be going into it ‘blindfolded’, we approached the on-site week with some premeditated concepts. The backbone of the program was already prepared, including most of the data transformations that needed to be done. This allowed for more flexibility when it came to integrating our solution into the client’s architecture, as well as conducting mandatory tests to ensure that everything ran smoothly.
With that said all work also had to be performed on their machines; we had to communicate in advance all the tools we would need, so they could be vetted for potential security vulnerabilities that might threaten their system and swapped for others if that was the case.
Arrival and Execution
The first step of the process depended on our ability to adapt our pre-made program to their system, which, we ended up discovering, involved moving Excel files to and from FileShare folders via Microsoft Access and validating the data through manual queries and checks. Documentation was lacking, so we frequently had to reach out to the client’s team (which at times was insufficient due to the extensive number of checks and the depth of knowledge required) and undertake exhaustive trials.
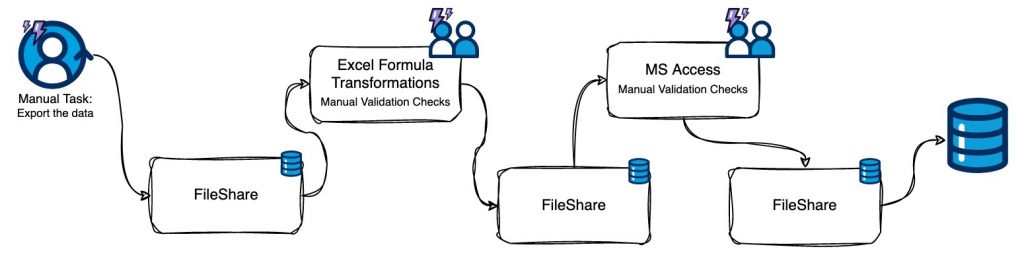
We faced two main setbacks, which required us to devise creative and unconventional solutions to overcome these challenges:
Integration with the pre-existing system
The first challenge was establishing a proper connection to their on-premise system, which relied on outdated technology, to ensure smooth integration with our data processing methods. Installing all the necessary tools to successfully deploy and run our program was not straightforward. Although we were using Python and SQL without any ‘fancy’ libraries, the required installations encountered obstacles that we needed to overcome due to their system’s versions and policies.
Building the bridge between the new system and the pre-existing infrastructure highlighted the complexity of the task, particularly because of the company’s size, which involved numerous moving parts and connections. Additionally, the documentation was either nonexistent or outdated. In this context, interaction with the client-side team became not just advantageous but essential for the success of the project. It also ensured that the solutions developed were closely aligned with the actual needs and workflows of the client.
Handling Data Privacy and Security
Now, the second challenge. Given the sensitive nature of financial data, privacy and security were of high importance. Therefore, problems naturally arose in ensuring that the systems complied with data protection regulations. Addressing these challenges required extra effort from our team that needed to adapt the solution to the new project demands.
The Full Circle
Following up our initial integration steps, this journey became even more unique when we faced the realization that we had to relocate to their headquarters (as previously mentioned) to fully deploy the project. This move introduced several unpredictable variables for which we could not prepare (aside from maintaining an open mind and a fearless approach) due to the ‘black box’ nature of their architecture and software.
Furthermore, we found ourselves constantly in limbo due to lack of permissions and issues with compatibility between the versions they could install ‘in-house’ versus the latest versions of the prerequisites needed for the project’s deployment. This unconventional scenario posed interesting challenges for us in understanding and adapting to the client-side architecture. This combined with their dependency on an on-premise system further complicated the development of our solution. However, despite all of these obstacles, we managed to pull through at the set deadline date.
Conclusion
This Journey of Data-Driven transformation at a Leading Vehicle Manufacturer marks a significant milestone in leveraging technology to enhance efficiency and decision-making capabilities. It definitely set a precedent for further improvements as the industries continue to embrace digital transformation, propelling the efficiency and quality of their services.
Our team’s experience with this project highlights the transformative potential of automation in revamping traditional business processes. It’s crucial to remember that, despite being in an era of digital transformation, the majority of tasks that are highly prioritized and of extreme importance to companies still rely on ‘old-school’ technology. This underscores the importance for data engineers to be able to swiftly adapt to unexpected situations. Being adaptable is one of your greatest assets in aiding the migration of these systems into the ‘new world’ of data automation.
A special thank you to Cátia Antunes and Paulo Souza for their insightful collaboration in this project.












