
Serverless Functions Explained: Fundamentals

Cloud computing has fundamentally changed the landscape of IT infrastructure. It allows businesses to leverage scalable, on-demand resources, reducing the need for large upfront investments in hardware. One of the most significant innovations in cloud computing is serverless architecture.
This will be a two-part article. This first one, aims to understand serverless functions, their advantages and challenges, and what techniques we can use to develop and test these functions locally.
We will go through:
- What is Serverless Architecture?
- How do Serverless Functions work?
- Serverless Functions Advantages
- What’s the catch?
- How can we develop and test?
What is Serverless Architecture
Before we explore serverless functions, it is essential to understand the foundation they are built on: serverless architecture. Serverless computing, despite its name, still relies on servers. However, the effort of managing these servers, its infrastructure, scaling it, and maintaining it, is done by a cloud provider like AWS, Azure, or Google Cloud, allowing the developers to focus on the development of the product itself. In a nutshell, you develop and deploy.
There are various subsets within the serverless computing paradigm, each having different functions and purposes. For instance, serverless functions, also known as Functions as a Service (FaaS), handle event-driven execution, Backend as a Service (BaaS) provides backend services like databases and authentication, and serverless databases automatically scale based on demand.
How do Serverless Functions work?
Serverless functions allow developers to execute small, modular pieces of code (functions) in response to events without worrying about managing the server infrastructure. But how do these functions work?
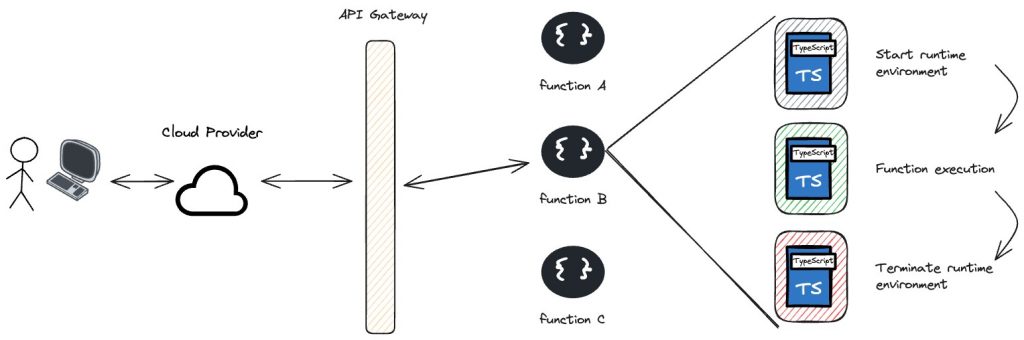
For a function to be executed we need to define a trigger. This could be an HTTP request, a database change, file uploads, scheduled time events (cron jobs), or messages from a queue. The way we define these triggers differs from the cloud provider we chose. For example, let’s consider a serverless function triggered by an HTTP request:
- User Request: A user makes an HTTP request to an API Gateway endpoint.
- API Gateway: The API Gateway receives the request and triggers the associated function.
- Function Execution: The cloud provider spins up a runtime environment for the function, executes the code, and processes the request.
- Response: The function processes the input (e.g., querying a database, processing data) and returns a response.
- Shutdown: Once the execution is complete, the runtime environment is terminated.
When a serverless function is invoked, its lifetime depends on its configuration. It can handle a single request and then terminate, remain active to handle multiple requests (up to a specific concurrency limit), or stay active for a set time to reduce delays for future requests.
One final key concept regarding these serverless functions is that a function is ephemeral and stateless, meaning it doesn’t retain any data or context between executions. If a state needs to be maintained, it must be stored in external services like databases or object storage.
Serverless Functions Advantages
Now that we know how serverless functions should work, let’s discuss why we should consider using a serverless architecture.
Scalability
When using traditional server-based models, we face a trade-off. If we only pay for the exact resources our application needs to run at a consistent number of requests, we might struggle to handle more traffic if the number of requests increases unexpectedly. On the other hand, if we pay for extra resources in case of growth, we might end up wasting money on unused resources if the traffic doesn’t increase. Serverless functions solve this problem by automatically adjusting the resources based on the number of requests. This means they can handle high traffic efficiently without wasting resources when traffic is low.
In contrast, while Kubernetes and VM autoscaling, for example, also provide automatic scaling, they typically cannot scale down to zero, which means there are always some baseline costs. Additionally, containers and VMs generally have longer startup times compared to serverless functions, leading to potential delays during traffic spikes.
Serverless functions not only offer faster response times by starting in milliseconds, but they also eliminate the need for infrastructure management, as the cloud provider handles all the underlying details. This makes serverless functions a cost-effective and efficient choice for applications with variable or unpredictable traffic, as they ensure resources are used optimally without the overhead and complexity of managing traditional server-based solutions.
Cost Efficiency
Serverless models charge you based on the precise amount of computing power and time your code requires to run. During periods of low activity, your costs are minimal, as there is no need to maintain idle servers. However, during high-traffic periods, the serverless infrastructure scales automatically, ensuring you only pay for the increased usage. This makes them an ideal choice for applications with variable or unpredictable traffic patterns, as it eliminates the need to over-provision resources in anticipation of peak usage times.
Serverless models charge based on the exact computing power and time your code requires to run (pay-per-use). If the number of requests decreases, the cost goes down accordingly, and if it increases, the cost scales up with usage. This makes them an ideal choice for applications with variable or unpredictable traffic patterns, as it eliminates the need to over-provision resources in anticipation of peak usage times or paying for idle time.
Reduced Operational Overhead
In traditional server-based models, engineers often spend lots of time configuring, provisioning, and maintaining servers, dealing with issues like scaling and other operational tasks. With serverless models, these responsibilities are passed to the cloud provider, allowing the engineers to focus only on writing and deploying code. As a result, this speeds up the development cycles and reduces maintenance efforts. Development teams can deliver new features and updates more often and efficiently, improving overall productivity.
Faster Time to Market
As we previously discussed, by removing the complexities of server management, the development cycles are shorter, and teams can bring new features to market much faster. As a result, not only keeps the product competitive but also allows for a faster time in response to user feedback and changing market demands. Overall, serverless promotes agility, enabling the team to innovate and iterate faster.
What’s the catch?
There’s a set of challenges when developing serverless functions. Since we don’t have to manage any server infrastructure, from a dev server to a test and production server, and we just need to deploy these functions to the cloud, how can we have a local environment that simulates the production environment? How can we make sure that when developing it locally it will behave the same way as in production? How can we develop and test locally a serverless function that interacts with one or more cloud services (e.g., AWS S3, DynamoDB, API Gateway)? How can we ensure that the local development environment has the same configurations, services, and integrations as the cloud provider?
Another issue is debugging, which in a serverless environment can be more complex due to the stateless nature of these functions and the lack of traditional debugging tools. Unlike traditional servers, we can’t attach debuggers to live serverless functions running in the cloud. In serverless platforms, the underlying infrastructure is abstracted away from the developer. You don’t have direct access to the servers or containers where your functions are executed. Debuggers often rely on low-level access to the runtime environment and process. Since serverless platforms abstract away this level of detail for scalability and manageability, attaching debuggers directly to the live functions is not feasible.
Ok! Enough with the problems and let’s look at how we can face these challenges!
How can we develop and test?
Deploying development and testing environments in the cloud to execute and evaluate our daily development work could potentially resolve the issue. However, managing multiple developer accounts could become overwhelming. Additionally, this approach might escalate expenses, as with serverless computing, we pay for the resources we use. Consequently, running functions in the cloud for testing purposes could incur significant costs. Keep in mind that it’s common to have a dedicated development or testing environment, preferably used for quality assurance or as a stage in your Continuous Integration and Continuous Delivery (CI/CD) pipeline, rather than directly testing your code in the cloud.
If developing directly in the cloud isn’t a good idea, what methods can we use? Let’s look at 4 different approaches:
Emulating Services
Emulating cloud services involves creating a local environment that mimics the cloud environment as closely as possible. This is a good approach when developing serverless applications because it allows developers to test and debug their code without needing to deploy to the cloud every time. This makes development faster and cheaper, as it avoids the costs associated with running cloud functions and helps catch errors early in a controlled environment. It provides a realistic environment for testing, ideal for end-to-end (e2e) testing and debugging complex interactions.
Mocking Services
Mocking involves creating fake implementations of cloud services where the responses and behaviour are predefined. It allows the developers to test their applications without making calls to the cloud. This is useful to isolate parts of the applications to run independent tests (unit tests), and generally faster when compared to the emulation of a service, since it’s not actually performing an operation.
Service Virtualization
This one might cause some confusion with mocking and emulating services, but it’s a different concept. Service virtualization creates virtualized versions of specific components. These virtualizations will simulate the actual behaviour when interacting with these components, allowing testing without requiring the actual services to be available. This method is often used when testing interactions between components (end-to-end testing).
Cloud Provider Testing Tools
Cloud providers often offer tools designed for testing serverless applications locally, like AWS SAM (Serverless Application Model) and Azure Functions Core Tools. These tools help simulate the cloud environment and provide a more realistic testing experience.
When comparing each method, none is better than the others. Mocking, emulating, and virtualizing might not completely replicate the real cloud environment, so they may not accurately show how things will work in production. Also, cloud provider testing tools might not cover all the scenarios you encounter in production. Each method has its use. Additionally, these methods support debugging within an IDE, except for cloud provider testing tools, which may or may not, depending on the tool.
We covered the good and the less good, on Part 2 let’s talk about how you can apply a serverless architecture in general.
What’s next?
On Part 1 of this article, we learned the basics of serverless functions, and the techniques to create a local environment to develop and test these functions.
In Part 2, we apply the theory by creating a local environment to run a serverless application, utilizing serverless functions and other cloud services. We will begin by defining a serverless application, selecting a cloud provider, understanding the necessary services from the cloud provider to run our application, identifying the tools required to emulate these services, and finally deploying and running the application locally.











