Implementing Change Data Capture (CDC) in Snowflake
A data warehouse is a relational database designed more for queries, data analysis, decision-making and Business Intelligence-type activities than for processing transactions or other traditional database uses.
The information stored in a data warehouse is historical and provides an overview of the different transactions that have taken place over time. Redundant data is often included in data warehouses to provide users with multiple views of information.
There are many data warehouse vendors in the market, but Snowflake is a modern data warehouse that has become an industry-leading cloud-based SaaS (Software-as-a-service) data platform.
Nowadays, data frequently changes in operational systems, but the data warehouse often doesn’t mirror this real-time updating, as the process of loading up-to-date information occurs at specified intervals rather than instantaneously.
Traditionally, businesses used batch-based approaches to move data once or several times a day, but this leads to latency and reduces the operational value of the data to the organisation.
Change Data Capture (CDC) has emerged as an ideal solution for near real-time data movement from relational databases (like SQL Server or Oracle) to data warehouses, data lakes or other databases, and can also work as batch processing (depending on how the job scheduling is configured).
In this article we will talk about Snowflake CDC and see how it keeps you updated with current data. But before getting started, let’s take a quick look at Snowflake and its most salient features.
What is Snowflake?
When it launched in October 2014, Snowflake was the first data warehouse solution designed to be delivered in the cloud, and it was called Snowflake Elastic Data Warehouse.
The idea was to offer users a solution, in the cloud, which would bring together all the data and task processes in a single data warehouse, whilst guaranteeing good performance in data processing, flexibility in storage, and ease of use.
Snowflake started with the following value propositions:
- Data warehousing as a service: Thanks to the cloud, Snowflake avoids typical infrastructure administration and database management problems. As with DBaaS, users can focus on processing and storing data, and by getting rid of the physical infrastructure, costs go down; and of course, it can always be adapted to the customer´s needs.
- Multidimensional elasticity: Unlike other products on the market at the time, Snowflake could scale up storage space and computing power independently for each user, making it possible to load data while running requests without having to sacrifice performance, as resources are dynamically allocated according to the needs of the moment.
- Single storage destination for all data: Snowflake allows all the company’s structured and semi-structured data to be stored centrally, so those wishing to work with this data can access it in a single system, without the need for prior processing before they start their analytical tasks.
Snowflake´s Unique Architecture
A Hybrid Architecture of Shared Disk and Share Nothing
Snowflake makes large-scale data storage and analysis possible thanks to its innovative architecture. Exclusively a cloud product, Snowflake is based on virtual computing instances, such as AWS Elastic Cloud Compute (EC2) for calculation and analysis operations, in addition to a storage service like AWS Simple Storage Service (S3) to store the data.
As with any database, a Snowflake cluster has storage resources (or disk memory), RAM, and CPU computing power. Snowflake is based on a hybrid architecture, blending a shared disk model with an isolated architecture known as Share Nothing Architecture.
On the one hand, all the data stored in the Snowflake data warehouse is consolidated into a single directory, like shared disk architectures, and is accessible to all the computation nodes in the cluster.
On the other hand, requests made on Snowflake using MPP (Massively Parallel Processing) calculation clusters are processed by nodes where each cluster contains only a portion of the data present in the data warehouse.
Based on these two approaches, Snowflake offers the simplicity of data management thanks to its centralised data space, combined with the performance of a Share Nothing architecture for queries on the data that the warehouse contains.
Snowflake´s Three Layers:
The Snowflake data warehouse comprises 3 layers:
- Data storage
- Request processing
- Cloud services
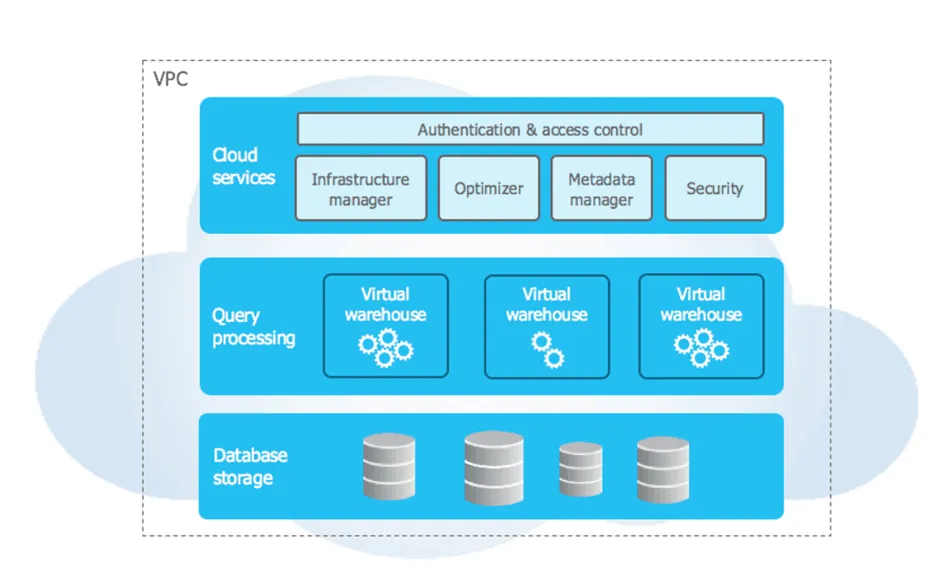
When data is loaded into your Snowflake warehouse, it compresses it, reorganises it into a column format, and enriches it with metadata and statistics. Raw data will no longer be accessible directly, but only via queries (SQL, R or Python) made through Snowflake.
Snowflake also incorporates a processing layer to handle queries on the data. Data queries are executed on virtual warehouses (or virtual data warehouses). Each virtual warehouse is an MPP cluster operating on a Share Nothing architecture, with multiple nodes, each storing a specific portion of the data warehouse’s overall data.
Each virtual warehouse can process a multitude of simultaneous requests, and the computing cluster can be scaled up or down depending on the workload. Importantly, the different virtual warehouses do not share any resources, be it computing power, memory, or storage: this design prevents resource conflicts and mitigates competition among requests for the same data.
Finally, cloud services form the top layer of the Snowflake infrastructure, facilitating seamless coordination across the data warehouse framework. These services allow users to authenticate, launch or optimise data queries, administer clusters, and leverage many other features.
Data Protection in Snowflake
Snowflake ensures the integrity of its hosted data through two key functionalities, Time Travel and Fail-safe.
Time Travel enables the preservation of data integrity by maintaining its state for the entire specified period, even after modifications have been made. Limited to a single day of history in the standard version, Time Travel can be configured for up to 90 days with the Snowflake Enterprise licence, and allows the restoration of previous states for tables, schemas, or entire databases.
The Fail-safe feature offers a 7‑day backup once the Time Travel period has ended, in order to recover data that might have been corrupted by errors during operations.
Both features help to maintain data integrity and also contribute to the billed storage capacity of the Snowflake cluster.
What is Change Data Capture (CDC)?
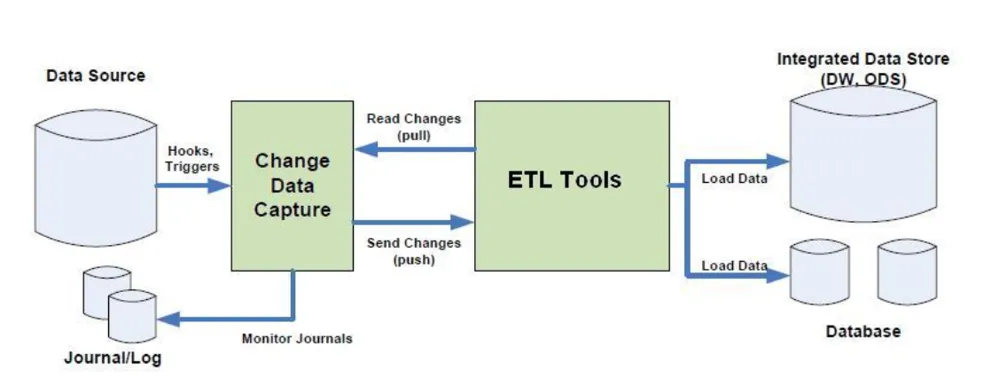
CDC is an ideal solution to capture the near real-time data movements in databases. It encompasses a set of software design patterns used to detect and track data changes. It triggers an event connected with data, causing a specific action to be executed for each CDC occurrence. In the context of data operations, the acquisition of real-time data streams is imperative for the efficient execution of analytics by any organisation, and CDC provides near real-time movement of data, processing it as soon as new database events occur.
Events are captured and streamed in real time using CDC, helping to achieve reliable, scalable, and low-latency data replication within high-velocity data environments. It eliminates the need for bulk data loading by implementing an incremental data loading procedure, so data warehouses or databases remain active in order to execute specific actions as soon as a CDC event occurs. What´s more, companies can send fresh data updates to BI tools and team members almost instantly with CDC!
What is Snowflake CDC and How Does It Work?
In today’s data-driven economy the information in your systems changes frequently, and it would be a complex task to load it fully into Snowflake every time it does, using up resources and money. This is where Snowflake Change Data Capture comes into play: you can implement CDC in Snowflake effectively with just a few commands, and this is made possible by the concept of streams in Snowflake.
A Snowflake stream object basically tracks all DML changes made to rows in a source table and stores the metadata of each change. This metadata, occurring between the two transactional time points in a table, is used later to retrieve the changed data.
What is a Snowflake Stream?
A stream in Snowflake, also known as a table stream, is an object that records DML changes made to a source object. It uses the metadata associated with those changes to enable operations on the changed data. A stream can provide a basic set of changes by leveraging the offset from its present placement to the current version of the table. When queried, a stream will return the historic data with the structure and nomenclature of the source object, alongside additional columns that provide more information about the type of change.
Let’s look at the additional columns returned as part of the result of the query to a stream.
METADATA$ACTION: The value of this column indicates the kind of DML operation that was recorded; the values are INSERT or DELETE. Note that the UPDATE statement is represented with two-row entries for INSERT and DELETE.
METADATA$ISUPDATE: This column indicates whether the row entry was part of an UPDATE statement. The value is TRUE for entries that were part of an UPDATE, and FALSE otherwise.
METADATA$ROW_ID: This specifies the unique and immutable ID for a row and can be used to track changes on a particular row over time.
What are the Types of Streams Available in Snowflake?
There are three stream types in Snowflake: standard, append-only, and insert-only; each serves a different purpose depending on your use case.
Standard: The standard stream type is supported for streams on tables, directory tables, and views. It monitors all DML changes in the source object (inserts, updates, and deletes), and also tracks table truncations. This stream type returns the net change in a row and does this by performing a join on the inserted and deleted rows within a change set. What this means, for example, is that if a row is inserted and then deleted between two transactional time points, a standard stream will not return it as part of the query. Because of this, a standard stream is also called a “delta stream” as it returns the net outcome of transactions executed on the data.
CREATE OR REPLACE STREAM my_stream ON TABLE my_table;
Append-only: Append-only streams exclusively track row inserts. Updates and deletes, including table truncations, are ignored by an append-only stream. For example, if 5 rows are inserted into a source object and 2 rows are deleted, a query to an append-only stream will return all 5 rows. Append-only streams are more performant than standard streams as they consume fewer resources as they only track inserts. Append-only is applicable to streams associated with standard tables, directory tables, and views.
CREATE OR REPLACE STREAM my_stream ON TABLE my_table APPEND_ONLY = TRUE;
Insert-only: Insert-only streams track row inserts only, like append-only streams; however, they are only supported on external tables. Files that are referenced by external tables on cloud storage locations are overwritten if an old file is deleted and a new one replaces it. Please note that the automatic refresh of external table metadata may not occur in all cases.
CREATE OR REPLACE STREAM my_stream ON EXTERNAL TABLE my_table INSERT_ONLY = TRUE;
What are Snowflake Tasks?
A task is also an object type in the Snowflake environment; it defines a recurring schedule for activities. It is recommended to use tasks to execute SQL statements, including statements that query data from the stored procedures. Moreover, developers can effectively manage tasks continuously and concurrently, considered the best practice for more complex, periodic processing.
Data pipelines are generally continuous, so tasks will use streams, which offer an enhanced approach for the continuous processing of new or modified data. Moreover, a task can also verify whether a stream contains changed data for a table. If no changed data exists, a task can determine whether the pipeline has consumed, altered, or skipped the data – this is why the use of Snowflake triggers is so widespread.
How to Set Up a Snowflake CDC with Streams
Let’s see how streams work through an example: consider a table named EMPLOYEES_RAW where the raw data is staged, and which ultimately needs to be loaded into the EMPLOYEES table.
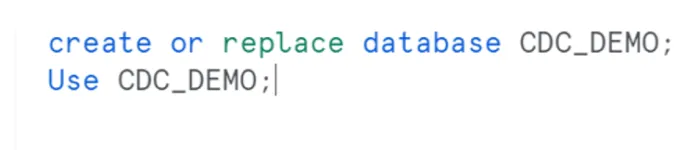
Firstly, you’ll need to create a database in Snowflake; you can do so using the following commands:
The table named EMPLOYEES_RAW is created and three records are inserted:

Now we´ll create the EMPLOYEES table, and the for the first load we´ll copy data from EMPLOYEES_RAW directly using an Insert statement:

The data now in the EMPLOYEES_RAW and EMPLOYEES tables is in sync. Let’s make a few changes to the data in the raw table and track these changes through a stream:

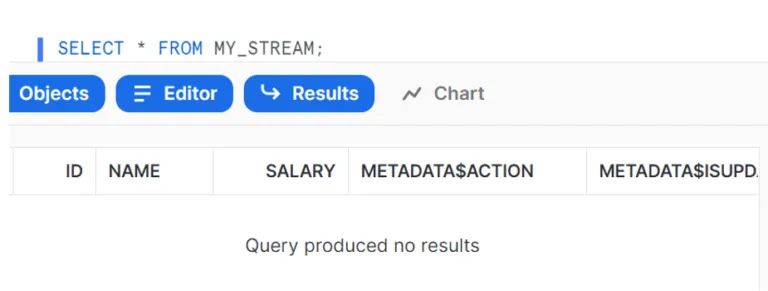
At the outset, when querying a stream, it will return null records as no DML operations have been performed on the raw table yet:
Let´s insert two records and update two records in the raw table, and then verify the contents of the stream called MY_STREAM:
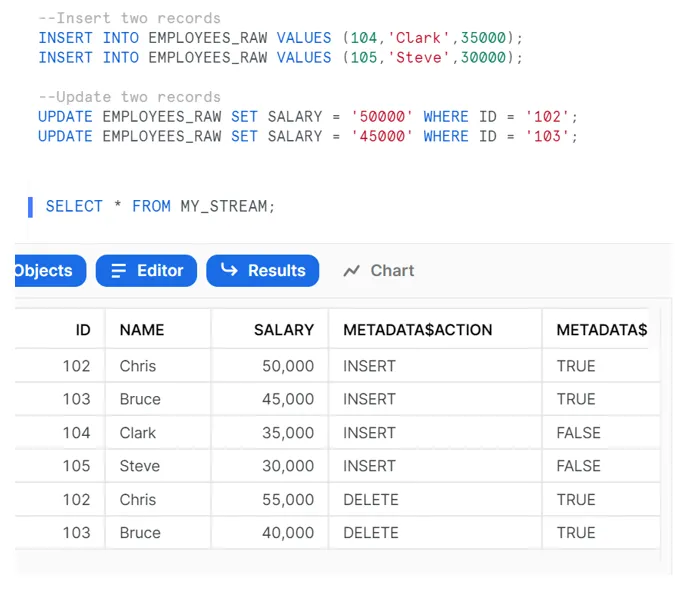
In the stream we can observe that:
- Employee records with IDs 104 and 105 have been inserted.
The METADATA$ACTION for these records is set as INSERT and METADATA$UPDATE is set as FALSE. - The employee records with IDs 102 and 103 which have been updated have two sets of records, one with METADATA$ACTION set as INSERT and the other as DELETE.
The field METADATA$UPDATE is set as TRUE for both the records, indicating that these records are part of an UPDATE operation.
Before consuming the data from the stream, let´s perform another DML operation on the already modified data and see how the stream updates its data:
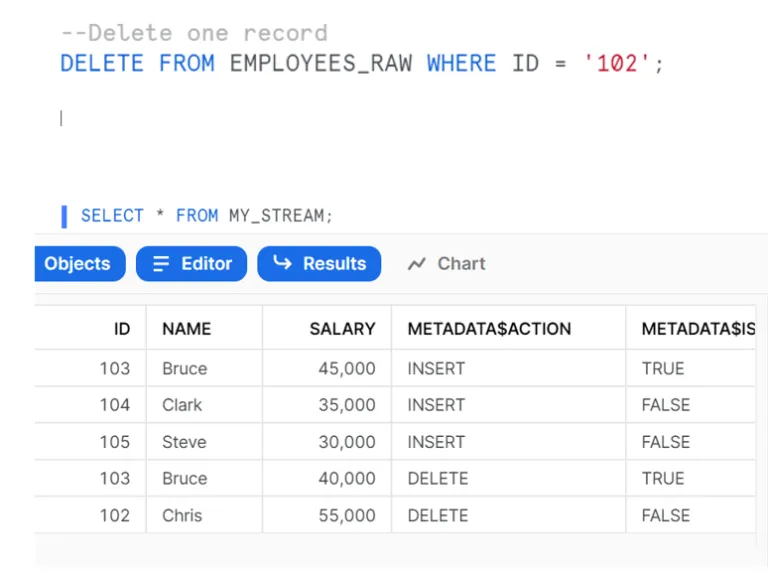
Note that streams record the differences between two offsets. If a row is updated and then deleted in the current offset, the delta change is a deleted row.
The same can be observed for the employee record with ID = 102, where the data is first updated and then the row is deleted. The stream only captures the delta change, which is a deletion.
In the above example, although we have inserted two records, updated two records and deleted one record, the final changes required to be captured from the raw table are two inserts, one update and one deletion.
The following select statements on the stream give the details of the records which need to be inserted, updated and deleted in the target table:
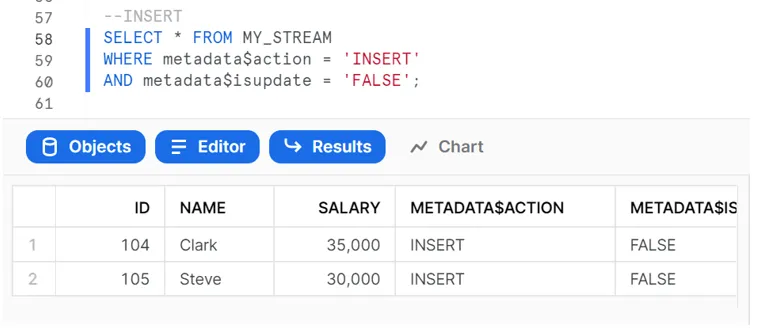
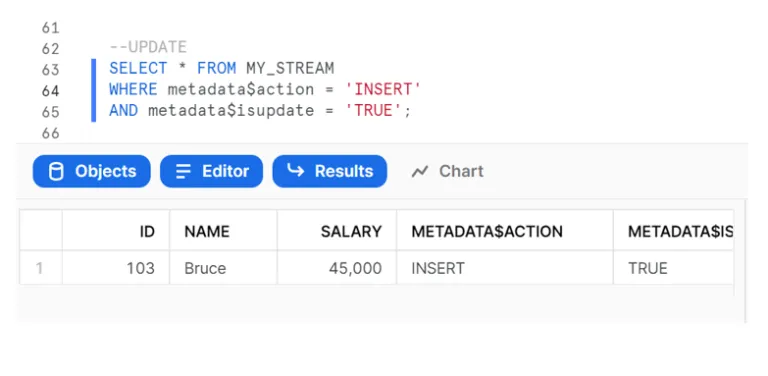
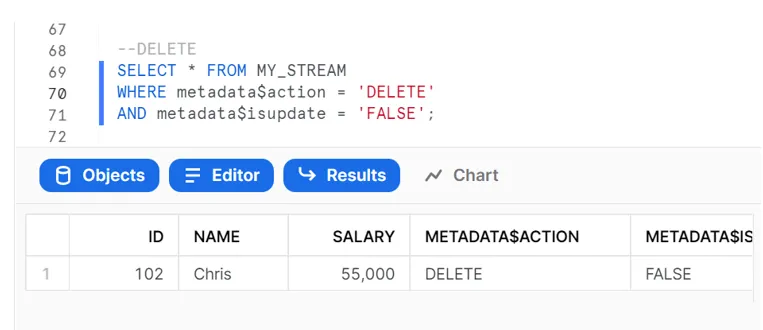
Finally, we can use a MERGE statement with the stream using these filters to perform the insert, update and delete operations on the target table, as shown below:

The image below shows that the merge operation inserted two records, updated one and deleted another, as expected.

Now that we have consumed the stream in a DML transaction, it no longer returns any records and is set to a new offset. So, if you need to consume the stream for multiple subsequent systems, the solution is to build multiple streams for the table, one for each consumer.
Stream Staleness
A stream turns stale when its offset is outside the data retention period for its source table. When a stream becomes stale, access to the historical data for the source table is lost, and this includes any unconsumed change records.
To view the current staleness status of a stream, execute the DESCRIBE STREAM or SHOW STREAMS command. The STALE_AFTER column timestamp indicates when the stream is currently predicted to become stale:
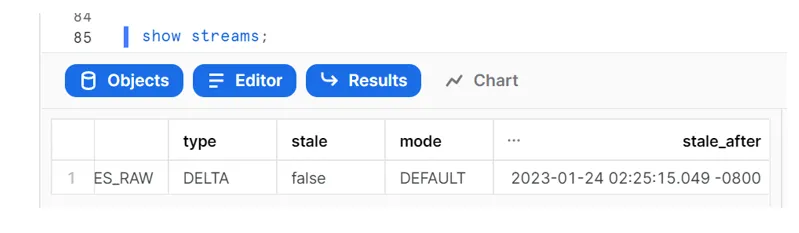
To avoid streams going stale, it is highly recommendable to regularly consume the changed data before its STALE_AFTER timestamp.
If the data retention period for a table is less than 14 days, and a stream has not been consumed, Snowflake temporarily extends this period to prevent it from going stale. The period is extended to the stream’s offset, with a default maximum of 14 days, regardless of the Snowflake edition associated with your account.
How to Schedule a Snowflake Stream with Tasks
Using Snowflake tasks, you can schedule a MERGE statement and run it as a recurring command line operation. In this section, using the same example as before, we will execute the MERGE command using tasks.
Run the SQL command given below to create a task:

Check the status of the task using this command:

By default, the task remains suspended after creation, as we can see below:

To start the task, run the following command:

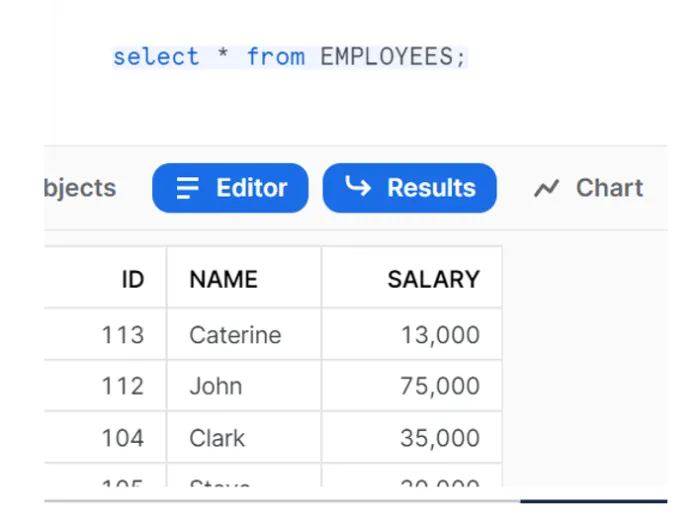
Now insert the CDC data into EMPLOYEE_RAW, and this dataset will subsequently appear as a stream dataset:

This query below will show you when the task will next run:

Conclusion
Snowflake Change Data Capture has totally replaced the traditional methods of implementing CDC. Although Snowflake is already an industry-leading cloud-based data platform known for its speed and flexible warehousing options, Snowflake CDC significantly enhances its value and utility.
Snowflake CDC really shines in cases where millions of records undergo transactions on a daily basis, but you only want to update the modified ones. Doing a full load will eat up your resources, so harness the power of Snowflake CDC and use the MERGE command to update the destination.
If you´d like further information or some assistance in leveraging Snowflake CDC, or if you have any other inquiries about cloud-based data platforms, don’t hesitate to get in touch with us! Our dedicated team of certified experts is ready to address your questions and provide any support that you might need.












