
The Art of Consolidation: Harmonizing a Multi-Tenant DWH in an On-Premises World

While cloud solutions are increasingly becoming the standard, many companies continue to rely on their existing on-premises systems – driven by regulatory requirements, specific security mandates, or historically grown infrastructures. However, the real challenge begins when these traditional systems are expected to serve as the foundation for future-facing technologies like AI or Advanced Analytics: For this, a harmonized, consistent data state is an absolute prerequisite.
In this post, we highlight an architecturally demanding scenario from the retail industry. We show how we transformed a complex on-prem multi-tenant DWH after the source systems had already been consolidated into a global unified system. We take a look at the exciting interplay between structural simplification at the source and the necessary logical precision in the Data Warehouse to master the bridge between historical depth and modern single-system logic.
The Data Ecosystem: From Local Silos to a Global Vision
To understand the complexity of this project, we must first look at the starting point. We are in a classic, internationally operating retail environment. In the original structure, each country maintained its own data with its own coding logic in an isolated, country-specific system. For IT, this meant: Every new country consequently meant another isolated ERP instance, its own article master data, and individual processes for recording sales.
This fragmentation was the obstacle to our overarching goal: the creation of company-wide analytical capabilities. To leverage synergies and control processes globally, the company wanted to move away from local isolated solutions. The vision was a unified, global system where all country data is maintained centrally. An article should have the same definition everywhere, and a process should run in Vienna exactly as it does in Berlin.
The Architecture of the Data Pipeline
In our underlying data architecture, the path of a record is clearly defined: data is ingested from various data sources through ETL jobs and transformed and staged as a first intermediate layer in dedicated country tables within an Operational Data Store (ODS) in relational format. Our philosophy here is to store the data as close to the source as possible to maintain full data lineage.
While data in the ODS is kept for only a fleeting period for operational purposes, the actual “refinement” takes place during the transfer to the Data Warehouse (DWH) system. The ODS data is transferred to the DWH system with technical validations, data enrichment, and data type cleansing. Here, the data is archived in country-separated schemas for more than ten years. This historized data forms the basis for our BI tools and enables sound, sustainable reporting over long time series.
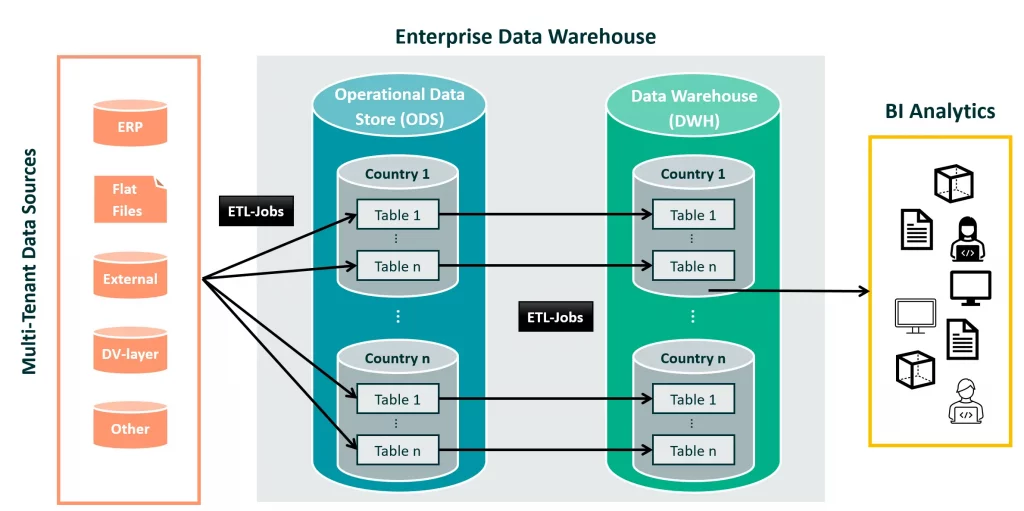
Target State Strategy: Anchoring the Global Vision in Existing Data Architecture
While the architecture described above forms the stable framework for data flow, this structure now collides with the changed reality of the new system vision. The introduction of a global unified system that harmonizes all country processes was a significant milestone for the IT landscape, but it presented us with two core questions in the DWH environment:
- How do we define which country each record belongs to? Previously, the world was relatively simple for us: country detection in the DWH was solved implicitly. Since the data flowed from physically separate source systems, we knew exactly which record belonged to which country by identifying the source, which fit perfectly with our multi-tenant DWH architecture. With the introduction of the harmonized unified system, this boundary disappeared. Suddenly, all data ended up “in one pot,” and we had to find new ways to precisely control the origin for our reports.
- How do we combine the harmonized logic and existing structures? A critical aspect of our country-separated data architecture was the historically grown isolation of codings. Since the source systems were operated separately by country for decades, deep semantic inconsistency prevailed. Article number 1234 in Hamburg could correspond to a completely different article with the same ID in Zagreb. Through harmonization, our declared goal was to consolidate these codings so that every ID has a unique, company-wide meaning. Only then could we ensure that analyses across different locations did not compare “apples and oranges.”
Thus, our data architecture with the strict separation into country-specific schemas in the DWH and years of historization was challenged in a positive way by the new source system. We had to develop a solution that seamlessly unites both the new “one-system world” and the “country-specific history.”
Strategic Planning: Why no “Big Bang”?
Faced with these challenges, the question of the implementation strategy arose. A complete “Big Bang,” i.e., the physical migration and complete re-coding of all historical stocks to the new logic, was not practical given limited on-prem server capacities and the enormous daily data volume in the terabyte range. Such a step would have paralyzed the systems for days and significantly increased the risk of data loss and inconsistencies.
We therefore decided on a hybrid architecture that combined security and progress: while the source now acted uniformly, we retained the tenant-specific separation in the DWH storage. The solution for the analytical layer was an abstraction layer with Union Views. These virtual layers logically merge the data from the different countries and present the BI applications with a harmonized overall picture with the country code as an additional functional key. This allowed us to keep performance stable without having to physically rewrite the proven historical database.
1. Core Question: How to achieve Country Assignment?
Since the source system no longer provided a physical separation, identifying suitable attributes for country detection was our first major hurdle. Such a feature must have two decisive properties: it must be used consistently across all countries and have a uniform meaning within the entire organization.
The Functional Perspective: Context is Everything
Behind the scenes of the SQL queries, the functional perspective plays a crucial role. We quickly learned that “country” is not equal to “country.” For logistical data in particular, it is a huge difference whether you perform the country assignment from the perspective of the Sales Organization (VKORG) or the Purchasing Organization (EKORG). Especially in international inter-company processes, purchasing and sales countries can differ. Data from a distribution center in a neighboring country that supplies a store in Germany must be flagged differently depending on the reporting requirement.
After a thorough business analysis and many interviews with the functional departments, we were able to identify the following attributes for this purpose, taking reporting requirements into account:
- Purchasing and Sales Organizations for logistical as well as operational or distribution data.
- Plant, Store, or Distribution Center IDs for real estate or assortment data.
- The Company Code or Controlling or Billing Area for financial and accounting data.
- Language Keys for master data with text or product descriptions.
Technical Implementation and ISO Standards
To implement country detection in a data-driven and future-proof way, we defined central reference tables. For consistent mapping, we consistently used the two-digit ISO-3166-Alpha‑2 format. In our ETL processes, the associated country code is automatically determined for each incoming ID via central lookups or User-Defined Functions (UDF).
Detailed View: Language Key as an Example
A particularly exciting feature for country detection of article descriptions in a retail system is the language key. However, two technical sticking points appeared right here, requiring a particularly sophisticated design of the ETL logic.
1. Handling Default Languages: In many systems, one language (often English or the corporate language) is defined as a “default.” This means: if no specific description is available in the national language, the default text is used. Technically, for our data architecture, this means: we must replicate these default records into all relevant country tables if no record in the national language exists for the primary key. To ensure that both entries do not end up in the DWH, we implemented a prioritization logic using a windowing function that checks in the final step before loading data into the DWH whether a record in the national language already exists. If so, the default entry is discarded.

2. Language Overlaps: The second challenge is geographical-linguistic in nature: countries like Germany and Austria or Serbia and Bosnia often share the same language key. Here, a simple 1‑to‑1 lookup in our multi-tenant DWH architecture is not sufficient. In such cases, we used a left join to replicate the records into the relevant country tables. This means that the data is multiplied if necessary—or specifically doubled in the case of Germany and Austria.

2. Core Question: Bridging the Gap between the Old and Harmonized World
The most complex functional challenge in this project was dealing with the over ten-year history. Since the new source system introduced a completely new, harmonized coding logic, we had to build a bridge between the old country-specific IDs and the new global keys.
Challenge 1: The Risk of ID Collision during Mapping
Before we turned to the technical details, we had to address an existential risk: ID overlaps between the old and new systems. Our architecture approach stipulates that new IDs from the source are first checked against mapping tables. If a translation is found, it is re-coded to the old ID. If none is found, it is processed as a new record. This ensures the analysis of historical data while simultaneously allowing new IDs from the harmonized system to be processed 1:1 in the DWH.
The danger: if a new ID (which has no translation) happens to be identical to an already existing old ID, historical data would be incorrectly overwritten. Suppose the new supplier Bienlein Logistik receives ID 65934 in the new system. Since Bienlein Logistik is new, there is no mapping for the ID. The ETL process would therefore write this ID 1:1 into the DWH. But in the DWH, the supplier Pingu Gutmann has already existed for years with exactly this old ID 65934. Without a strict separation of number ranges, the system would overwrite the historical data of Pingu Gutmann with the information from Bienlein Logistik. This “clash” had to be strictly excluded in advance through a careful definition of the new number ranges for critical attributes such as supplier or article numbers.
Challenge 2: Data Type Conflicts
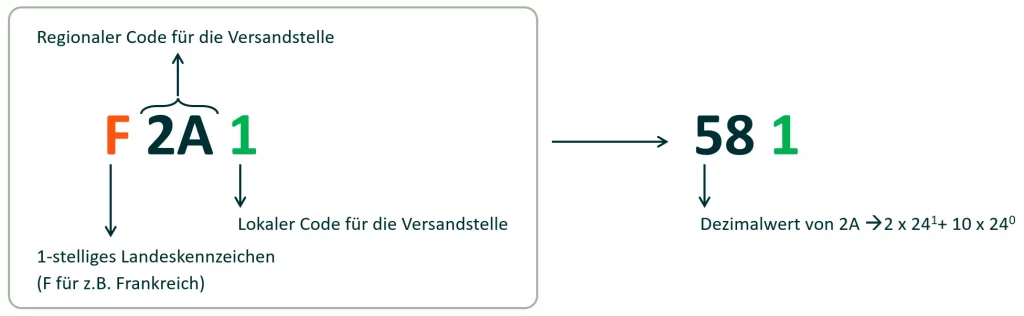
A technical highlight was the harmonization of Shipping Points. In the on-prem DWH, the Shipping Point attribute was defined as SMALLINT (up to 32,767). However, the business department wanted new IDs that would contain a country and regional feature to make the origin recognizable at first glance for the functional users.
Since we could not change the data type globally, we used a technical trick: Base-24 encoding. The new ID consists of a letter for the country, a 2‑digit regional number in Base 24, and a local sequential number. Mathematically, this allowed the business department to define up to 575 (24 * 24 – 1) different shipping point IDs – a comfortable buffer upwards. Technically, we converted the Base-24 component into a decimal value and simply appended the sequential number to lead the IDs mathematically back into the existing SMALLINT logic while ensuring the IDs remained unique.
Challenge 3: Dynamic Number Ranges
For attributes like Document Numbers (invoices, orders), we primarily referred to the current fiscal year. From the migration onwards, for example, invoice numbers were defined as 10-digit with a leading “8”. This re-coding is largely implementable independently of the deep history, as the new harmonized number range takes effect from the new fiscal year anyway. Nevertheless, cross-company functional expertise was required here to ensure that number ranges for different document types were defined consistently across all countries.
Summary: Technical Milestones of Harmonization
Looking back at the project, the central technical successes can be summarized in three pillars:
- Virtual Consolidation instead of Physical Migration: The decision against the “Big Bang” and in favor of the Union View architecture was the key to success. It allowed us to make the new, harmonized source world immediately usable while the petabytes of historical data remained secure and performant in their original schemas.
- Intelligent Identification in the ETL Layer: By using ISO standards and context-dependent attributes (such as VKORG/EKORG or language keys), we successfully reconstructed the lost country-specific identity of the data in the harmonized data stream.
- Mathematical Bridges: Solutions like Base-24 encoding show that technical limitations (such as rigid data types in on-prem systems) can be overcome through mathematical logic without sacrificing data integrity.
Conclusion: Data Engineering as a Bridge between Business and Technology
The harmonization of a multi-tenant DWH in an international retail environment is far more than a pure database operation. It is a process that requires a deep understanding of the business history, the logistical processes, and a clear vision for the future.
We learned that successful harmonization at the source (the “one-system goal”) inevitably creates new tasks in the DWH. The art of data engineering here consists of absorbing these requirements through intelligent mapping logics and virtual layers.
Today, our system is far more than just a digital archive. It is a consistent, company-wide foundation. The bridge between the “old” country-specific world and the “new” global logic is built – providing the perfect launchpad for Advanced Analytics and AI projects that rely on a clean, historized data base. On-prem is not an obstacle in this context, but—with the right tricks—a highly stable and powerful platform for the future.












