
The Data Quality (DQ) Accelerator is a comprehensive solution designed to accelerate the delivery of trusted data across an enterprise. It bridges the gap between buying off-the-shelf software and building a custom framework from scratch.
The Data Quality (DQ) Accelerator is a comprehensive solution designed to accelerate the delivery of trusted data across an enterprise. It bridges the gap between buying off-the-shelf software and building a custom framework from scratch.
The Data Quality (DQ) Accelerator is a comprehensive solution designed to accelerate the delivery of trusted data across an enterprise. It bridges the gap between buying off-the-shelf software and building a custom framework from scratch.
Data quality isn’t just a “nice to have”—it’s the foundation of reliable analytics and AI. Every enterprise eventually faces the “Build vs. Buy” dilemma, and having implemented both industry leaders like Ataccama, Informatica, and Collibra as well as custom-built frameworks, we’ve seen the pros and cons of each.
Our DQ Accelerator bridges this gap by blending the best of both worlds: it combines the scalable power of enterprise platforms with the lean agility of a custom-coded solution, allowing you to move from messy data to AI-ready insights in days rather than months.
The accelerator follows a structured methodology to transform “Bad Data” into “Trusted Insights”:

A 4‑week engagement to define a tailored Data Governance (DG) program aligned with strategic goals

Users define data quality rules for specific datasets. A dedicated engine executes these rules automatically

Results are stored in a standardized base data model for consistency

Front-end dashboards and alerts consume the results to provide real-time visibility
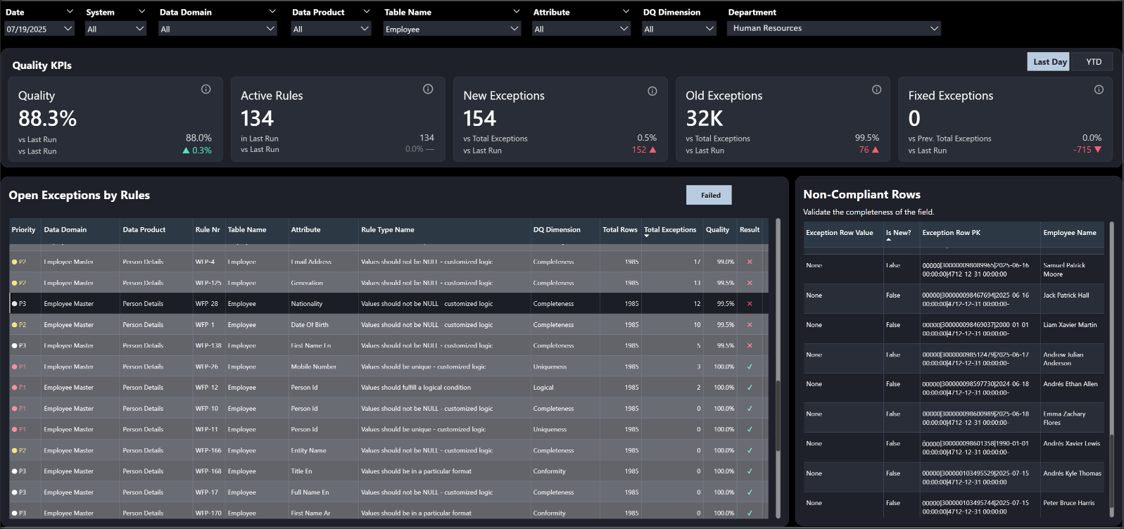
The DQ Accelerator addresses the average annual loss of $12.9M that businesses face due to poor data quality by replacing slow, manual checks with automated and consistent processes. This solution provides the high-quality foundation necessary for accurate AI and analytics outputs while accelerating the discovery of quality gaps through on-demand features like AI-driven rule recommenders and automated data profiling. Furthermore, the system ensures transparency and continuous improvement by reporting specific invalid row IDs and tracking issue resolution through historical KPI reports that monitor quality evolution over time.
Built on a highly adaptable architecture, the tool supports major platforms such as Snowflake, Databricks, Cloudera, and Oracle using diverse engines like Spark, Python, and native SQL. While the solution has been extensively tested in Oracle environments, its flexible architecture ensures seamless compatibility with other RDBMS, including MS SQL Server, PostgreSQL, and MySQL. It can be extended to meet specific enterprise needs with a GUI for rule editing and a robust life cycle management process for rule deployment across development, UAT, and production environments. To ensure proactive governance, the framework integrates alerting systems and workflow automation to notify data stewards of quality issues while maintaining high scalability and parallelism across all supported database flavors.



You will shortly receive an email to activate your account.

