Evaluating LLM Applications (2/2)

A Deep Dive Case Study into Methodologies and the RAGAS Library
In our previous article, we explored why systematic evaluation of LLM applications is crucial for enterprise success and introduced RAGAS as a framework for addressing this challenge. Now, we’ll demonstrate how to put these concepts into practice through a detailed technical case study that showcases concrete implementation strategies and results.
While our first article focused on the strategic importance of evaluation for decision-makers, this deep dive is designed for technical practitioners, developers, ML engineers, and data scientists who look for practical insights on implementing robust evaluation pipelines for their LLM applications.
Case Study: Evaluating an LLM Application for Document-Based Q&A
A Fortune 500 technology enterprise wanted to empower their investor relations team with an AI solution that could quickly extract insights from shareholder communications. The team regularly spent hours manually researching questions from analysts, investors, and internal stakeholders about competitor positioning and market strategy. With quarterly earnings calls approaching and increasing pressure to position their company against market leaders, they needed a solution that could reliably answer complex questions while ensuring factual accuracy.
The business objectives were clear:
- Reduce research time from hours to minutes
- Ensure responses reflect only factual information from official documents
- Provide competitive intelligence insights with proper context and attribution
- Scale the solution to handle hundreds of inquiries during peak periods
To demonstrate RAGAS in practical application, let’s examine this enterprise LLM application designed to answer questions based on shareholder letters from four major IT companies published in 2023. This case study illustrates how systematic evaluation transforms subjective assessments into quantifiable metrics, providing clear insights for optimization.
The tested system architecture consists of three key components working in concert:
- An LLM (gpt-4o-mini, which is fast and cost effective) serving as the answer generation engine
- A vector database storing embedded chunks of shareholder letters for information retrieval
- A reranker component that prioritizes the most relevant content before passing it to the LLM
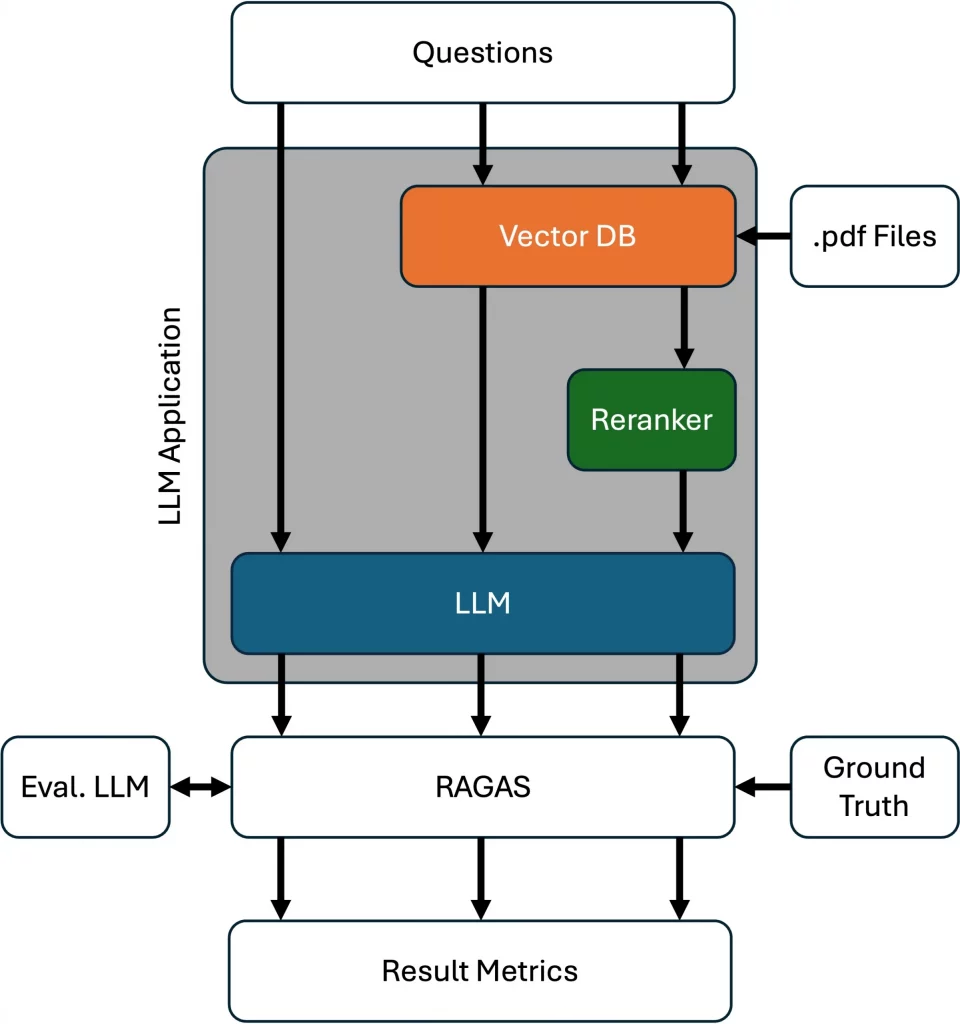
Our evaluation approach tested three progressively enhanced configurations to measure the impact of each component:
- LLM Alone: The baseline configuration where the model generates responses using only its internal knowledge
- LLM + Vector Search: Augmenting the LLM with relevant document retrieval
- LLM + Vector Search + Reranker: The complete system with prioritized content selection
For each configuration, we presented the same 20 questions from a predefined test set. Our test questions ranged from specific data points to more complex analytical queries, all with corresponding ground truth answers extracted from the source documents. Here is an example question:
{
"question": "What initiatives reduced Amazon's cost to serve per unit in 2023?",
"reference_answer": "Regionalization and logistics optimization reduced U.S. costs by more than $0.45 per unit",
}The evaluation pipeline collected the question, retrieved context (or used an empty context if not applicable), generated answer, and ground truth answer to create a comprehensive evaluation dataset.
{
"question": "What initiatives reduced Amazon's cost to serve per unit in 2023?",
"reference_answer": "Regionalization and logistics optimization reduced U.S. costs by more than $0.45 per unit",
"retrived_contexts": ["...", "...", "...", "...", "..."],
"llm_answer": "1. **Fulfillment Network Efficiencies**: Improvements in the fulfillment network helped offset increased costs.2. **Regionalization**: Re-architecting the network to store items closer to customers improved delivery speeds and efficiency. 3. **Expansion of Same-Day Facilities**: Increasing the number of items delivered same day or overnight by nearly 70% YoY enhanced service efficiency.4. **Improvements in Operations**: Enhancements to customer self-service features and operational improvements reduced customer service contacts per unit.",
}This structured dataset was then analyzed using RAGAS, which employs a sophisticated evaluation methodology. For objective assessment, we utilized GPT-4o as the judge model, a more powerful and comprehensive model than the one generating the answers. This architectural separation ensures unbiased evaluation across multiple performance dimensions, similar to how human evaluators with greater expertise might assess the work of junior analysts.
This methodology transforms LLM application evaluation from subjective analysis into a structured, data-driven process with clear numerical outputs. The evaluation pipeline automatically processes inputs and outputs through each system component, allowing for controlled comparison between configurations while maintaining consistent testing conditions across trials.
Evaluation Metrics and Results
RAGAS offers specialized metrics designed specifically for RAG system evaluation, focusing on key aspects of reliability and performance:
- Context Precision: Measures how much of the retrieved information is directly relevant to the query
- Context Recall: Assesses how comprehensively the system retrieves necessary information
- Context Entity Recall: Evaluates how well the system captures specific named entities required for accurate responses
- Faithfulness: Determines whether the generated answer aligns factually with the retrieved data
- Answer Relevancy: Measures how directly the response addresses the user’s specific query
- Noise Sensitivity: Quantifies how often the system generates errors due to irrelevant or misleading data
All metrics are normalized between 0 and 1, where higher values indicate better performance for most metrics (a score of 0.85 in Context Precision means 85% of retrieved information is relevant), except for Noise Sensitivity where lower values are preferable (a score of 0.2 indicates the system is less prone to being misled by irrelevant information).
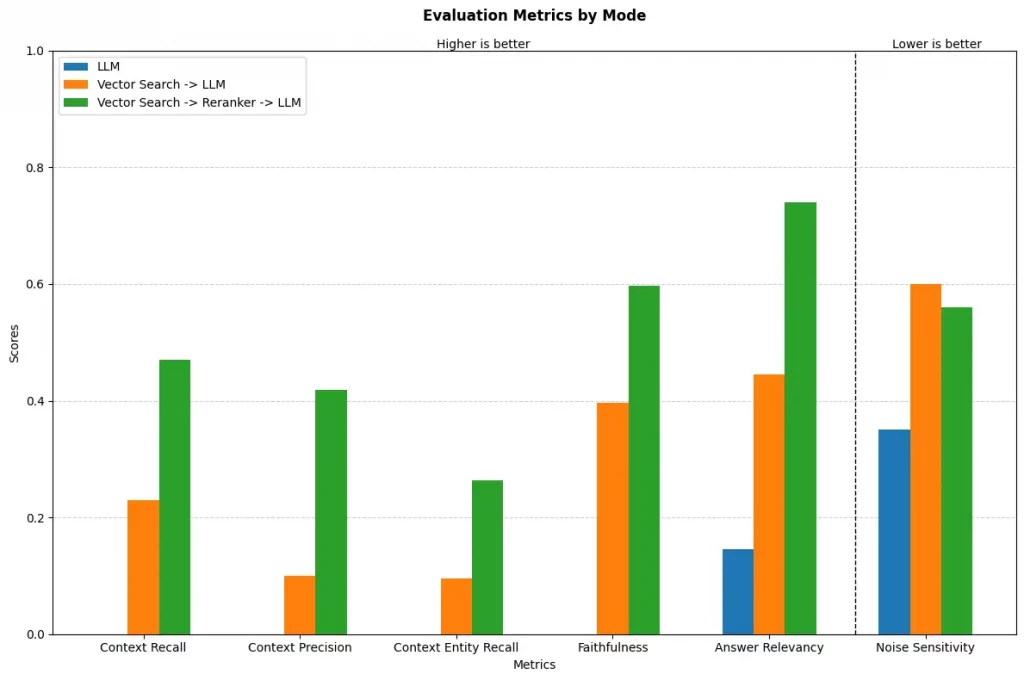
The evaluation results reveal a clear progression in system performance across configurations, with broader patterns emerging at both system and metric levels.
At the highest level, we observe substantial performance improvements as we move from the baseline LLM to the fully integrated system. The most significant gains appear when adding the reranker component, highlighting its critical role in filtering and prioritizing relevant information.
Looking more closely at specific metrics:
Context Quality Metrics (Recall, Precision, Entity Recall):
The LLM alone shows no context quality (0.0) as expected, lacking access to external knowledge, adding vector search improves recall but with moderate precision. The reranker significantly enhances precision (0.20 → 0.40) while maintaining high recall (0.22 → 0.48).
Response Quality Metrics (Faithfulness, Answer Relevancy):
The baseline LLM struggles with faithfulness (0.0) and shows limited answer relevancy (0.15), vector search improves both metrics moderately. The reranker configuration achieves substantial gains in both faithfulness (0.60) and answer relevancy (0.69).
Error Susceptibility (Noise Sensitivity):
The baseline LLM shows low noise sensitivity (0.35), indicating priorization of no answer instead of hallucinations caused by the missing context. Vector search reduces this with more or less relevant informtion to around 0.60 but still exhibits vulnerability to misleading information. The reranker reduces noise sensitivity again (0.51), but room for improvement remains.
These results demonstrate that while retrieval augmentation provides a foundation for knowledge grounding, the reranker plays a crucial role in distinguishing between relevant and irrelevant information. By prioritizing the most pertinent context, the reranker helps the LLM focus on generating accurate, targeted responses while reducing the likelihood of incorporating misleading information.
Despite these impressive improvements, the evaluation also reveals opportunities for further optimization. Even in the best configuration, metrics remain below optimal levels, suggesting potential enhancements in several areas:
- Chunking Strategies: Refining how documents are segmented before embedding could improve retrieval precision
- Retrieval Parameters: Optimizing vector database configuration for more relevant results
- System Prompts: Enhancing instructions to the LLM for better context utilization
- Document Processing: Improving how structured information is parsed and prepared for embedding
This multitude of adjustable parameters presents a perfect opportunity for systematic hyperparameter tuning. By leveraging RAGAS metrics as objective functions, developers can implement grid search, Bayesian optimization, or other systematic search strategies to identify optimal configurations, similar to how traditional machine learning models are tuned. For example, one might optimize chunk size, retrieval k‑value, and reranker threshold simultaneously to maximize faithfulness while maintaining minimum thresholds for context precision. This approach transforms LLM application development from intuition-driven experimentation to data-driven optimization.
This case study demonstrates how RAGAS provides quantifiable insights that can guide iterative system improvement, turning subjective observations into actionable development priorities.
Broader Implications and Future Directions
LLM application evaluation is not merely a technical necessity, it’s a strategic advantage for organizations deploying these systems in production environments. By establishing continuous monitoring and iterative improvement cycles, organizations can maintain system quality even as usage patterns and requirements evolve.
Key areas for future innovation in LLM application evaluation include:
- Automated test set creation: The RAGAS team is actively working on reducing the manual effort required to generate ground truth data, potentially using LLMs themselves to create diverse, representative test cases at scale.
- Long-term performance monitoring: Integrating RAGAS metrics into MLOps workflows could enable detection of performance drift over time, alerting teams when system quality degrades due to data shifts or changing user behaviors.
- Automated prompt optimization: When other system components remain static, RAGAS can evaluate how prompt modifications affect overall performance. This creates opportunities for automated systems that iteratively refine prompts based on evaluation feedback, continuing until performance meets predetermined quality thresholds.
Conclusion: The Future of LLM Application Evaluation
As LLMs become embedded in mission critical enterprise applications, robust evaluation frameworks will separate effective deployments from unreliable ones. The RAGAS library provides an indispensable toolset for both developers and decision makers, offering a quantifiable, scalable approach to measuring LLM application performance.
Although challenges such as evaluation variability and language specific biases remain, continuous advancements in LLM assessment will drive the next wave of AI reliability. Businesses that adopt systematic evaluation strategies today will be best positioned to unlock the full potential of LLM technology in the future.
For those looking to dive deeper, RAGAS documentation and our sample notebook offers further insights into implementation best practices. Whether you’re optimizing retrieval pipelines or making strategic AI investments, understanding LLM application evaluation is key to building truly impactful AI applications.
Further sources:
- GitHub Repository for this Blog, including code example
- Ragas Documentation
- Paper about Ragas