Evaluating LLM Applications (1/2)

Why does it matter?
Large language models (LLMs) have moved beyond experimental phases to become mission-critical in modern enterprises. From customer service automation to advanced knowledge retrieval, these models are transforming industries. However, with this rapid adoption comes a significant challenge — how do we ensure their reliability, accuracy, and effectiveness?
Unlike traditional machine learning models, LLM applications lack well-established evaluation standards, forcing developers and decision-makers to rely on subjective judgment or ad hoc testing. Without robust assessment methods, businesses risk deploying systems that generate misleading responses, undermine user trust, and fail to meet operational goals.
This article explores why systematic evaluation is crucial, introduces the RAGAS library as a powerful solution, and provides a real-world case study to demonstrate its practical application. Whether you’re a developer optimizing retrieval-augmented generation (RAG) systems or a stakeholder assessing LLM integration, this guide will help you navigate the complexities of model evaluation with confidence.
Why LLM Evaluation Matters
Imagine a customer support team using an LLM-powered system to answer technical questions. A customer asks about configuring a critical security feature, but the system confidently provides outdated instructions due to retrieval failures. The customer implements these incorrect settings, leading to a security breach, significant downtime, and ultimately, damaged trust in the business relationship.
This scenario highlights a critical gap in today’s AI landscape: while standalone LLMs are rigorously evaluated through standardized benchmarks like MMLU (which tests multitask knowledge across 57 subjects) and HELM (a holistic benchmark evaluating models on diverse tasks), the integrated systems that actually deliver business value receive far less scrutiny. Companies invest heavily in selecting the best foundation models but often overlook evaluating how these models perform when embedded within their specific business processes, knowledge bases, and application stacks.
Assessing the performance of LLM applications is not just about accuracy, it’s about ensuring reliability in complex workflows that deliver tangible results and business value. Many enterprise LLM applications don’t function in isolation; they integrate retrieval mechanisms, reranking algorithms, and domain-specific constraints in a well defined system landscape of a company. A failure in any of these components can degrade overall performance, leading to:
- Inconsistent or misleading responses that erode trust and customer loyalty.
- Reduced operational efficiency due to retrieval errors, negating cost-saving benefits.
- Financial risks from incorrect or low-quality outputs that may require expensive remediation.
Traditional evaluation methods, such as benchmarking large language models on standard datasets, fail to capture these intricacies and complex environments where real business value is created or destroyed. Fully evaluating integrated LLM systems delivers immense business value by protecting revenue, maximizing ROI, mitigating legal risks, building competitive advantage, and accelerating time-to-value across AI-augmented workflows.
The Limits of Traditional Testing Approaches
When evaluating LLM applications, traditional software testing concepts prove insufficient due to the fundamental differences in behavior and outputs. While standard software produces deterministic results from specific inputs, LLMs generate varied, non-deterministic responses even to identical prompts. This variance makes traditional unit and integration testing approaches almost impossible to implement effectively. The nature of natural language outputs also presents unique challenges that classical software validation methods weren’t designed to address.
Similarly, classical machine learning metrics fall short when applied to sophisticated LLM applications. Text outputs require semantic evaluation rather than simple classification metrics like accuracy or precision. The question of whether a generated response correctly captures the meaning of a ground truth answer is inherently more complex than binary classification tasks, demanding more nuanced evaluation methods tailored to language models.
The Current Evaluation Gap
In our experience with enterprise clients, we observe that subject matter experts and developers typically rely on manual, qualitative assessments to evaluate LLM application outputs. While some evaluation frameworks exist, systematic testing remains the exception rather than the rule in most organizations. This common approach lacks consistency across evaluators, cannot scale to enterprise needs, provides no quantitative benchmarks for improvement tracking, and makes it difficult to compare different implementations or versions.
This gap has created an urgent need for a systematic, quantitative approach to evaluating LLM-powered applications, especially for mission-critical enterprise deployments.
Introducing RAGAS: An LLM-Native Evaluation Framework
RAGAS (Retrieval-Augmented Generation Assessment System) was designed to address this evaluation challenge by combining the best elements from software testing and machine learning assessment methodologies. It provides structured, repeatable tests with quantifiable metrics that enable systematic comparison and tracking.
The framework provides quantitative metrics that help developers identify weak points in their LLM applications, such as hallucinations, irrelevant document retrieval, or poor response generation. The framework is open-source and integrates with popular evaluation libraries (LangChain, LangSmith, Llama Index, etc.), making it increasingly adopted as a standard for benchmarking.
Next to traditional NLP metrics as well as presence and exact matches of strings, RAGAS relies on a new concept built on the principle of “LLM as a Judge.”
The LLM as a Judge Paradigm
The “LLM as a Judge” approach represents a fundamental shift in evaluation methodology. Rather than relying solely on human evaluations or simplistic metrics, this approach leverages LLMs themselves to assess outputs against specific criteria.
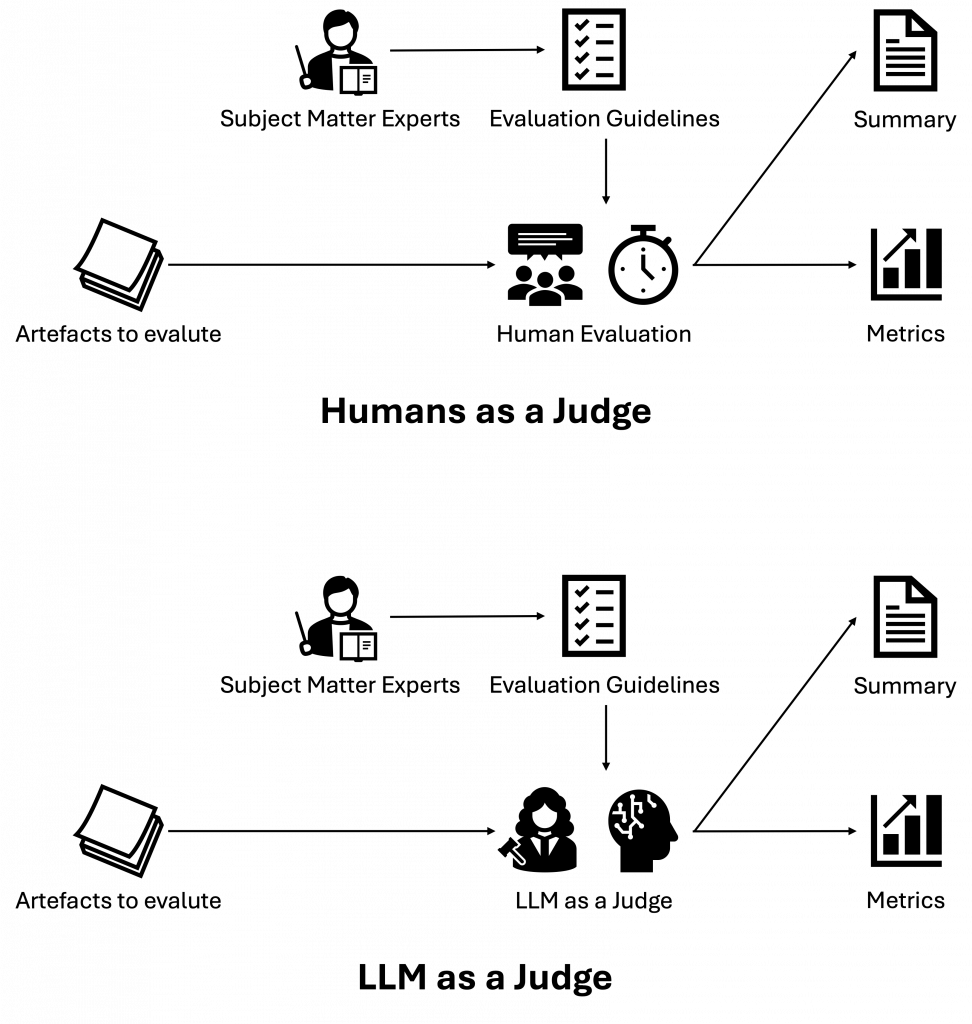
In this paradigm:
- Subject matter experts define evaluation criteria and guidelines
2. Instead of human reviewers conducting each evaluation, an LLM serves as judge
3. The judge LLM applies consistent standards across thousands of examples
4. Results are condensed into quantitative metrics and qualitative insights
LLM as a Judge refers to the use of Large Language Models to automatically assess and evaluate software artifacts where human judgment was traditionally required. LLMs evaluate outputs from other AI systems against specific criteria like quality, accuracy, and guideline adherence. This approach scales evaluation processes that would be prohibitively expensive to perform manually, offering consistent application of standards across large volumes of content. While LLM judges may occasionally struggle with nuanced context or introduce biases from their training data, they still provide a practical and repeatable alternative to human evaluation. In many settings, LLM-based evaluation can reduce costs significantly compared to expert human reviewers, making it a compelling solution for iterative testing and continuous monitoring.
RAGAS: A Comprehensive LLM Application Testing Framework
RAGAS stands out as a powerful framework specifically designed for evaluating LLM applications, particularly retrieval-augmented generation systems. Its key benefits include:
- Quantitative assessment: Transforms subjective judgments into numerical metrics
- Comprehensive evaluation: Measures multiple dimensions from context quality to answer relevance
- Scalable testing: Automates evaluation across thousands of examples
- Integration-friendly: Works with popular LLM application frameworks like LangChain and LlamaIndex
- Evidence-based improvement: Identifies specific weaknesses to prioritize development efforts
RAGAS employs core concepts in its metrics to address key challenges effectively. Each metric is designed with robust principles to ensure objective and reliable evaluations across diverse use cases. These principles emphasize a single-aspect focus for clarity, intuitive interpretability for accessibility, and consistent scoring ranges for meaningful comparisons. As a result, RAGAS provides quantifiable benchmarks that enable systematic model comparison, performance monitoring, and reliable progress tracking for LLM applications.
Alternatives to RAGAS
Next to RAGAS, other evaluation frameworks with similar design and capabilities exist that support RAG-style assessment across both retrieval and generation components. DeepEval offers a modular, pytest-like interface with built‑in metrics such as contextual precision, recall, faithfulness, and answer relevancy, the same dimensions captured by RAGAS, while also enabling rich metric customization and interactive reasoning. ARES automates synthetic query generation and trains lightweight model‑based judges to score context relevance, faithfulness, and answer quality with minimal human labels. RAGChecker provides fine‑grained diagnostics, offering separate metrics for retrieval accuracy (e.g. claim recall, context precision) and generation behavior (e.g. hallucination, context utilization, faithfulness).
Summary
RAGAS empowers both domain experts and developers throughout the entire lifecycle of LLM application development and operation. During development, it provides quantitative feedback that guides systematic improvements. In production, it enables continuous monitoring to detect performance degradation before it impacts users.
For managers and stakeholders, implementing robust LLM application evaluation delivers substantial business benefits:
- Risk mitigation: Quantifiable quality metrics help identify potential failure points before deployment
- ROI optimization: Performance benchmarks ensure investments in LLM technologies deliver measurable returns
- Confidence in decision-making: Objective measures replace subjective opinions when selecting models or approaches
- Operational visibility: Monitoring dashboards provide early warning of degrading performance
- Competitive advantage: Systematically improved applications deliver superior customer experiences
By transforming subjective assessments into quantitative metrics, RAGAS bridges the evaluation gap that has slowed enterprise adoption of LLM technologies. Organizations can now make data-driven decisions about model selection, system architecture, and deployment readiness with confidence.
In our next article, we’ll provide a technical deep dive into RAGAS implementation through a practical case study. We’ll demonstrate how this framework transforms LLM application evaluation from an art to a science, with concrete examples and implementation guidance for technical teams.